Intel Discloses New Details On Meteor Lake VPU Block, Lays Out Vision For Client AI
by Ryan Smith on May 29, 2023 9:00 AM EST- Posted in
- CPUs
- Intel
- Machine Learning
- Movidius
- VPU
- NPU
- Meteor Lake

While the first systems based on Intel’s forthcoming Meteor Lake (14th Gen Core) systems are still at least a few months out – and thus just a bit too far out to show off at Computex – Intel is already laying the groundwork for Meteor Lake’s forthcoming launch. For this year’s show, in what’s very quickly become an AI-centric event, Intel is using Computex to lay out their vision of client-side AI inference for the next generation of systems. This includes both some new disclosures about the AI processing hardware that will be in intel’s Meteor Lake hardware, as well as what Intel expects OSes and software developers are going to do with the new capabilities.
AI, of course, has quickly become the operative buzzword of the technology industry over the last several months, especially following the public introduction of ChatGPT and the explosion of interest in what’s now being termed “Generative AI”. So like the early adoption stages of other major new compute technologies, hardware and software vendors alike are still in the process of figuring out what can be done with this new technology, and what are the best hardware designs to power it. And behind all of that… let’s just say there’s a lot of potential revenue waiting in the wings for those companies that succeed in this new AI race.
Intel for its part is no stranger to AI hardware, though it’s certainly not a field that normally receives top billing at a company best known for its CPUs and fabs (and in that order). Intel’s stable of wholly-owned subsidiaries in this space includes Movidius, who makes low power vision processing units (VPUs), and Habana Labs, responsible for the Gaudi family of high-end deep learning accelerators. But even within Intel’s rank-and-file client products, the company has been including some very basic, ultra-low-power AI-adjacent hardware in the form of their Gaussian & Neural Accelerator (GNA) block for audio processing, which has been in the Core family since the Ice Lake architecture.

Still, in 2023 the winds are clearly blowing in the direction of adding even more AI hardware at every level, from the client to the server. So for Computex Intel is disclosing a bit more on their AI efforts for Meteor Lake.
Meteor Lake: SoC Tile Includes a Movidius-derived VPU For Low-Power AI Inference
On the hardware side of matters, the big disclosure from Intel is that, as we have long suspected, Intel is baking some more powerful AI hardware into the disaggregated SoC. Previously documented in some Intel presentations as the “XPU” block inside of Meteor Lake’s SoC tile (middle tile), Intel is now confirming that this XPU is a full AI acceleration block.
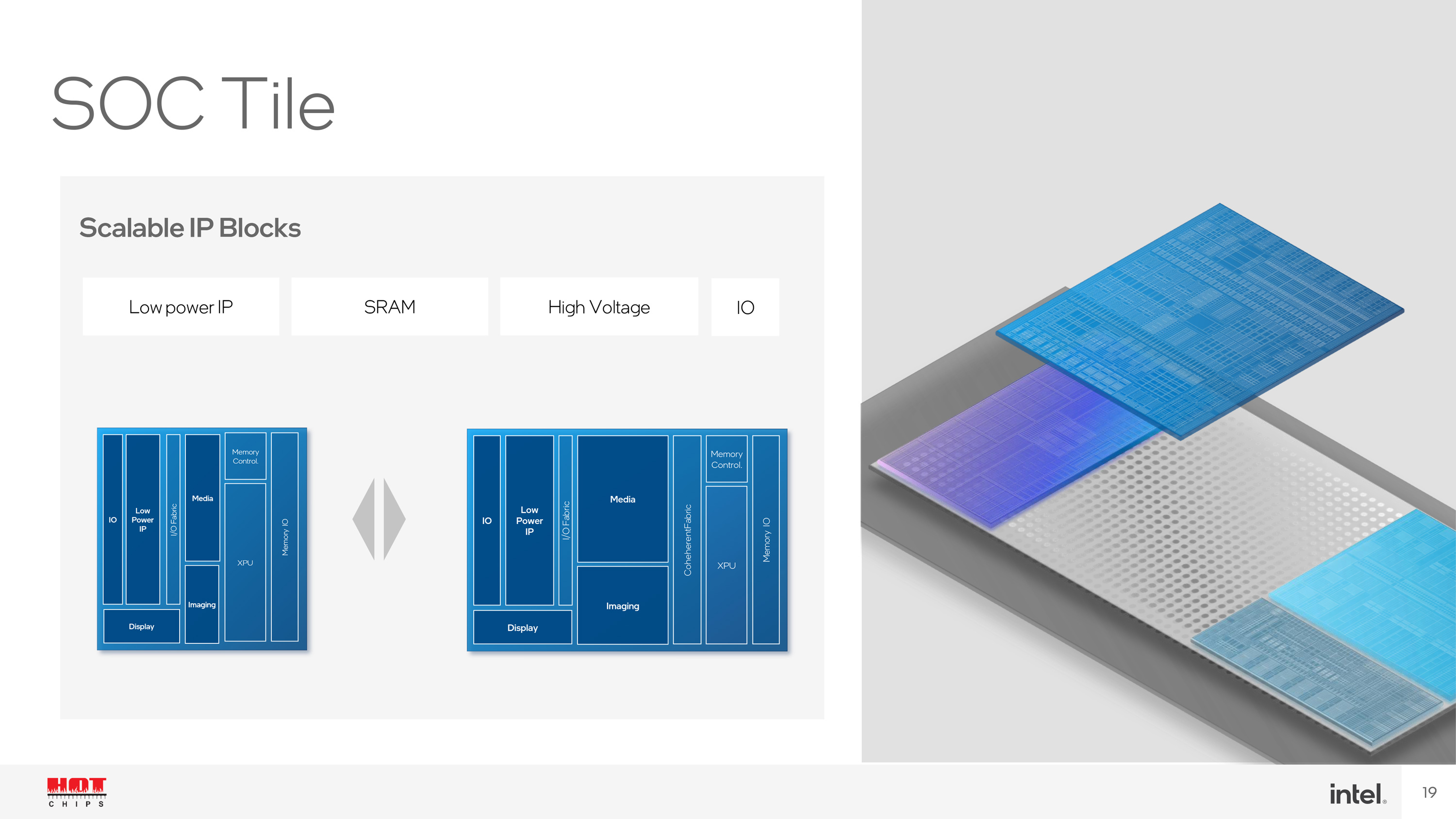
Specifically, the block is derived from Movidius’s third-generation Vision Processing Unit (VPU) design, and going forward, is aptly being identified by Intel as a VPU.
The amount of technical detail Intel is offering on the VPU block for Computex is limited – we don’t have any performance figures or an idea of how much of the SoC tile’s die space it occupies. But Movidius’s most recent VPU, the Myriad X, incorporated a fairly flexible neural compute engine that’s been responsible for giving the VPU its neural network capabilities. The engine on the Myriad X is rated for 1 TOPS of throughput, though at almost 6 years and several process nodes later, Intel is almost certainly aiming far higher for Meteor Lake.

As it’s part of the Meteor Lake SoC tile, the VPU will be present in all Meteor Lake SKUs. Intel will not be using it as a feature differentiator, ala ECC or even integrated graphics; so it will be a baseline feature available to all Meteor Lake-based parts.
The purpose of the VPU, in turn, is to provide a third rail option for AI processing. For high-performance needs there is the integrated GPU, whose sizable array of ALUs can provide relatively copious amounts of processing for the matrix math behind neural networks. Meanwhile the CPU will remain the processor of choice for simple, low-latency workloads that either can’t afford to wait for the VPU to be initialized, or where the size of the workload doesn’t justify the effort. That leaves the VPU in the middle, as a dedicated but low-power AI accelerator to be used for sustained AI workloads that don’t need the performance (and the power hit) of the GPU.
It's also worth noting that, while not explicitly in Intel's diagrams, the GNA block will also remain for Meteor Lake. It's speciality is ultra-low-power operation, so it is still needed for things like wake-on-voice, and compatibility with existing GNA-enabled software.
Past that, there’s a lot left we don’t know about the Meteor Lake VPU. The fact that it’s even called a VPU and includes Movidius tech implies that it’s a design focused on computer vision, similar to Movidius’s discrete VPUs. If that’s the case, then the Meteor Lake VPU may excel at processing visual workloads, but lack performance and flexibility in other areas. And while today’s disclosure from Intel disclosure quickly brings to mind questions about how this block will compare in performance and functionality to AMD’s Xilinx-derived Ryzen AI block, those are questions that will have to wait for another day.
For now, at least, Intel feels that they are well positioned to lead the AI transformation in the client space. And they want the world – developers and users alike – to know.

The Software Side: What to Do With AI?
As noted in the introduction, hardware is only one-half of the equation when it comes to AI accelerated software. Even more important than what to run it on is what to do with it, and that is something that Intel and its software partners are still working on.
At a most basic level, including a VPU provides additional, energy-efficient performance for executing tasks that are already more-or-less AI driven today on some platforms, such as dynamic noise suppression and background segmentation. In that respect, the inclusion of a VPU is catching up with smartphone-class SoCs, where things like Apple’s Neural Engine and Qualcomm’s Hexagon NPU provides similar acceleration today.

But Intel has their eyes on a much larger prize. They both want to foster moving what are currently server AI workloads to the edge – in other words, moving AI processing to the client – as well as fostering entirely new AI workloads.
What those are, at this point, remains to be seen. Microsoft laid out some of its own ideas last week at their annual Build conference, including the announcement of a copilot function for Windows 11. And the OS vendor is also laying some groundwork for developers with their Open Neural Network Exchange (ONNX) runtime.
To some degree, the entire tech world is at a point where it has a new hammer, and now everything is starting to look a whole lot like a nail. Intel, for it’s part, is certainly not removed from that, as even today’s disclosure is more aspirational than it is about specific benefits on the software side of matters. But these truly are the early days for AI, and no one has a good feel for what can or cannot be done. Certainly, there are a few nails that can be hammered.

To that end, Intel is looking to foster a “built it and they will come” ecosystem for AI in the PC space. Provide the hardware across the board, work with Microsoft to provide the software tools and APIs needed to use the hardware, and see what new experiences developers can come up with – or alternatively, what workloads they can shift on to the VPU to reduce power usage.
Ultimately, Intel is expecting that AI-based workloads are going to transform the PC user experience. And whether or not that entirely happens, it’s enough to warrant the inclusion of hardware for the task in their next-generation of CPUs.














17 Comments
View All Comments
GhostOfAnand - Monday, May 29, 2023 - link
Whichever of Intel's VPU block or AMD's AI block allow the closest to the metal programming with open documentation will win. None of this gimmicky OS specific or vendor specific AI "enhancements" will do. If both firms don't do this, they'll cede the entire market to Nvidia when they eventually enter the consumer market with silicon for Windows on Arm. Mark my words.dotjaz - Monday, May 29, 2023 - link
You are just talking shit. Closest to the Metal requires vendor lock in. That's literally what means. It tailors to one specific microarchitecture or ISA.Dolda2000 - Sunday, June 4, 2023 - link
>Closest to the Metal requires vendor lock in. That's literally what means.No, it also means being able to implement back-ends for otherwise standardized interfaces and optimizing the same.
TristanSDX - Monday, May 29, 2023 - link
So it is baseline feature but only for mobile in order to save energy. On desktop AI workload will be routed to GPU / CPUnandnandnand - Tuesday, May 30, 2023 - link
Not what I've heard:https://videocardz.com/newz/intel-shows-off-16-cor...
"Intel Meteor Lake is now expected to launch by the end of this year for laptops. The company hasn’t commented on reports that Meteor Lake-S was canceled, but it’s possible that such processors will be released. What may also be important to note is that VPU will be available on all Meteor Lake CPUs, including the supposed desktop “F” variants which usually lack integrated graphics support."
There's been some confusion over whether or not Meteor Lake will come to desktop. But getting the AI accelerators into everything needs to be done sooner rather than later, and is probably being demanded behind the scenes by the likes of Microsoft and Adobe.
Even if it's not as important as it is for mobile, it would still be nice to pick up any Intel CPU made in 2024+ and get modest AI acceleration (outperforming the iGPU if nothing else). Same goes for AMD. Putting an iGPU in every AM5 CPU released so far was a nice move that makes their CPUs more versatile. Hopefully they put XDNA in all Zen 5 desktop CPUs.
tipoo - Monday, May 29, 2023 - link
I gather this VPU ported to a new node and higher clocked might be around 4TOPS? The M2 is like 16? Or is this not comparable?Ryan Smith - Monday, May 29, 2023 - link
Until we know more about the architecture, meaningful comparisons are going to be hard to make. Useless ALUs are easy to throw at things, so FLOPS alone is not a very helpful metric.aiculedssul - Tuesday, May 30, 2023 - link
from what I can see in the Linux patches (found'em via Phoronix), the API seems to be NN-only; looks a bit like a subset of what was available for the Keem Bay SoC's, with none of the ISP/CV APIs (available for M2/MX/KB) being made available.so it doesn't look like just old IP on a new node (then again, the Movidius stuff were all SoC's, so maybe Intel just picked the parts they wanted); I'd love to see some benchmarks, but I guess we'll have to wait a bit for those.
it's a bit confusing, as the V in VPU apparently now stands "Versatile" as opposed to "Vision"; so while not mentioning "vision" matches the lack of a Computer Vision-related API, it's hard to imagine how having less makes it "versatile" :)
nandnandnand - Monday, May 29, 2023 - link
Stable Diffusion benchmarks now!noobmaster69 - Tuesday, May 30, 2023 - link
This seems misguided on Intel’s part. I’m a huge believer in AI and the benefits to society, putting dedicated silicon for AI inference into laptops and desktops seems like a waste of transistors. For data center, I get the use case for high power chips that are dedicated for that purpose. Likewise, in very power constrained environments (such as mobile phones operating <5w), I can see the benefit in power savings and battery longevity. But on the desktop I’m really struggling to find a use case where generic CPU cores running at 100w couldn’t get the job done ‘good enough’ for consumers. What applications are out there today where AI inference is being done locally on the desktop? I can’t think of a single example of where this would even be used.