Arm Announces Neoverse Infrastructure IP Branding & Future Roadmap
by Andrei Frumusanu on October 16, 2018 1:30 PM EST
Among of the first announcements coming out of Arm’s TechCon convention in San Jose, is the unveiling of Arm’s new infrastructure branding and a sneak peek at the product roadmap for the next 3 years.
Up till today, the Arm’s IP portfolio for the infrastructure market didn’t differentiate itself much from the regular consumer IP. Today this now changes, as Arm tries to convey its dedicated focus in this market. The new IP portfolio which will see broader announcements over the coming months and years, is now dubbed “Arm Neoverse”.

The Neoverse branding is supposed to be live alongside the usual consumer device oriented Cortex IP branding, meaning that at some point we’ll see a new Neoverse CPU announced whose use-cases are meant to be in the infrastructure space.
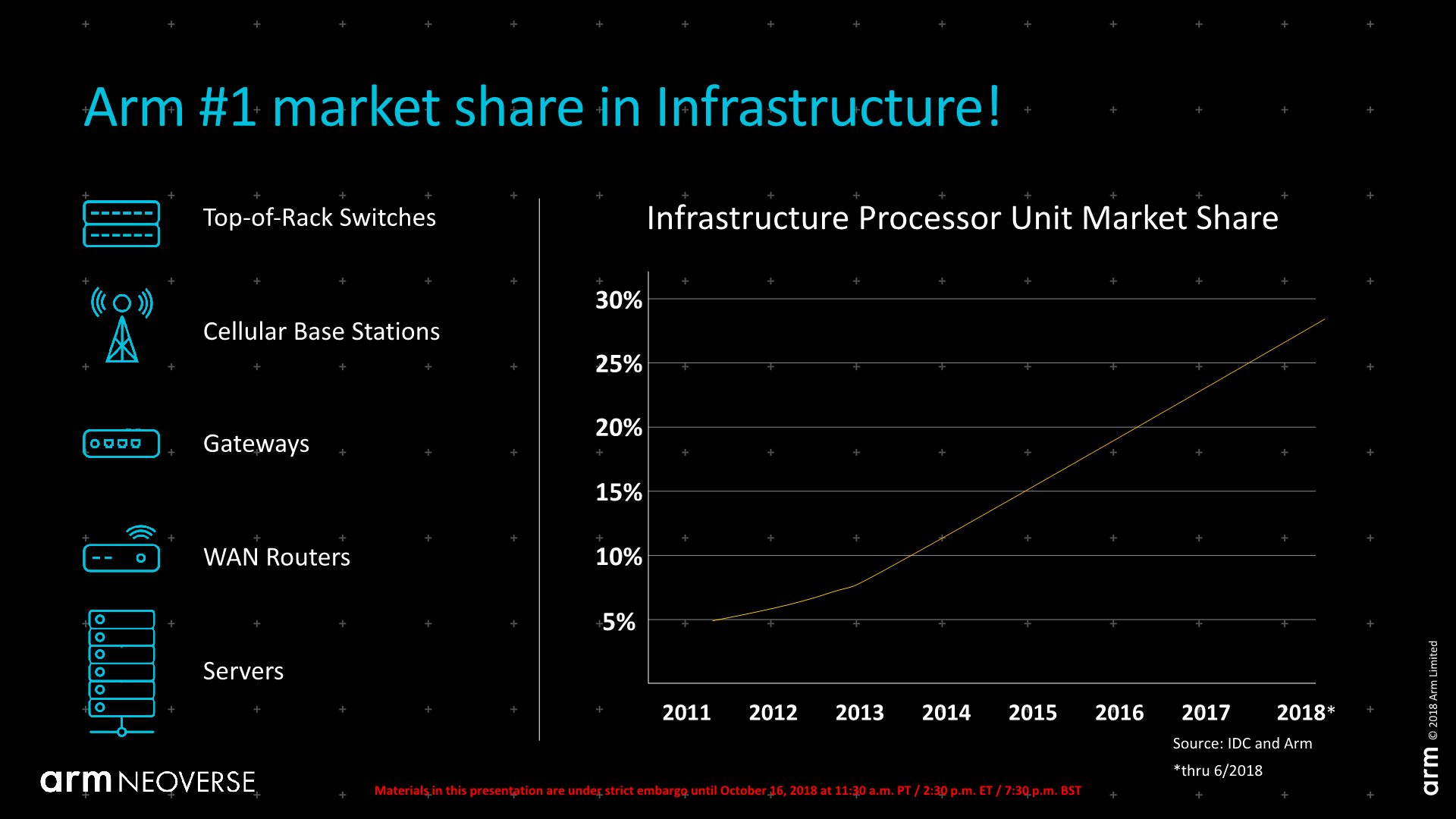
Arm showcases that over the last several years, they’ve been able to capture a significant amount of market share in infrastructure devices. What infrastructure devices actually means, is any kind of non-end user device, such as networking equipment, going from switches, base stations, gateways, router, and most importantly also servers. Here the various Arm vendors have reportedly gained up to a 28% market share.

The biggest surprise today was that Arm again has publicly published the roadmap for the next several years, revealing the codenames of the infrastructure focused CPU and platform IPs. As such, we finally see the Ares, Zeus, and Poseidon codenames acknowledged. The CPU IPs based on these codenames should be the sever-oriented counterparts to Enyo/A76, Deimos and Hercules, the latter of which would remain under the Cortex branding. What the differences between the Cortex and Neoverse cores are is still unclear, but among the many possibilities, it’s not hard to imagine that we’ll be seeing SVE implemented in the server IP first.
Arm is also seemingly pushing the performance projections, and promises a 30% jump in performance for each generation over the coming years. This figure is more aggressive than the 20 to 25% quoted CAGR for the Cortex based CPUs in consumer devices, so we’ll likely see more differentiation in the infrastructure IPs.
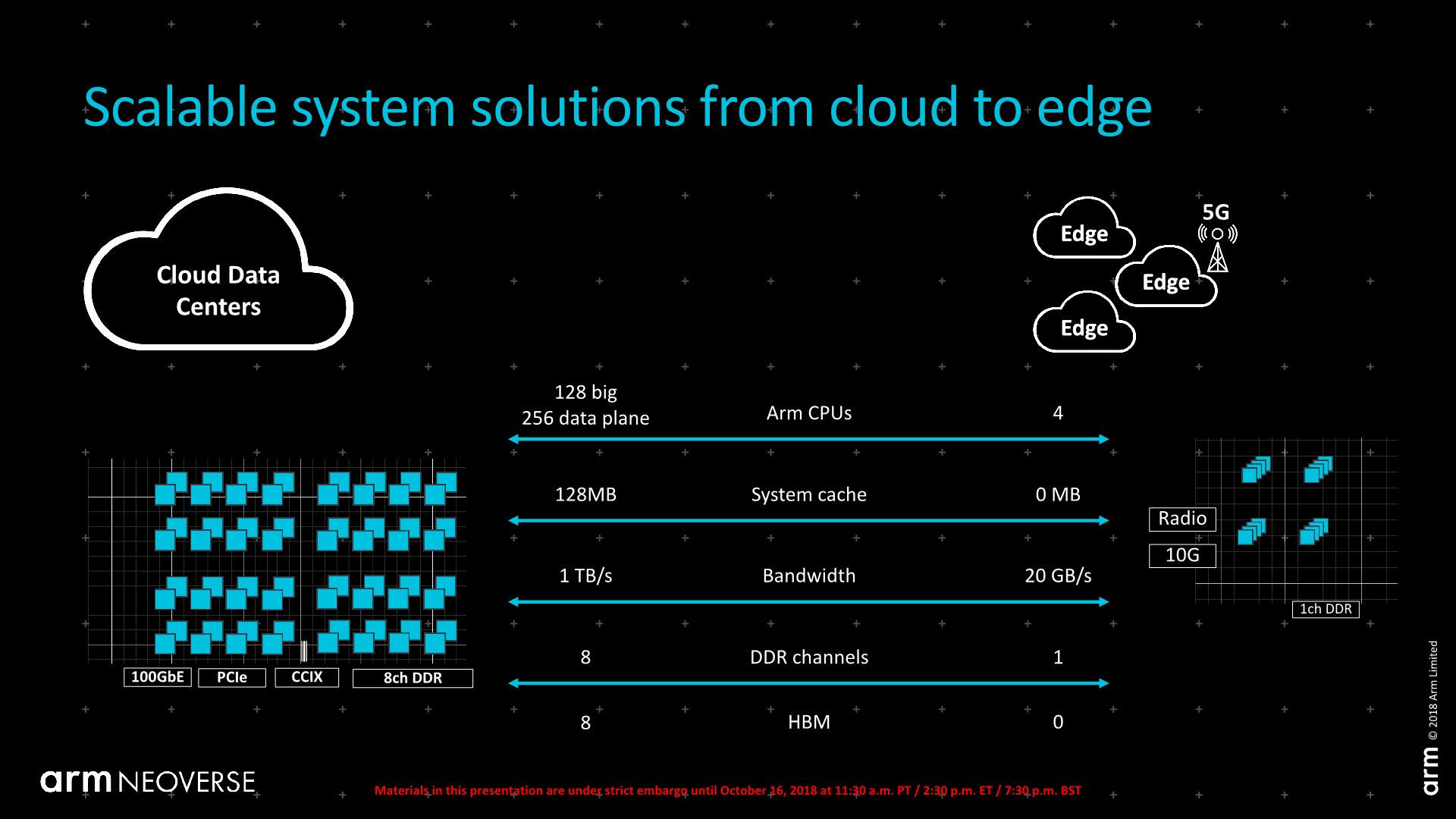

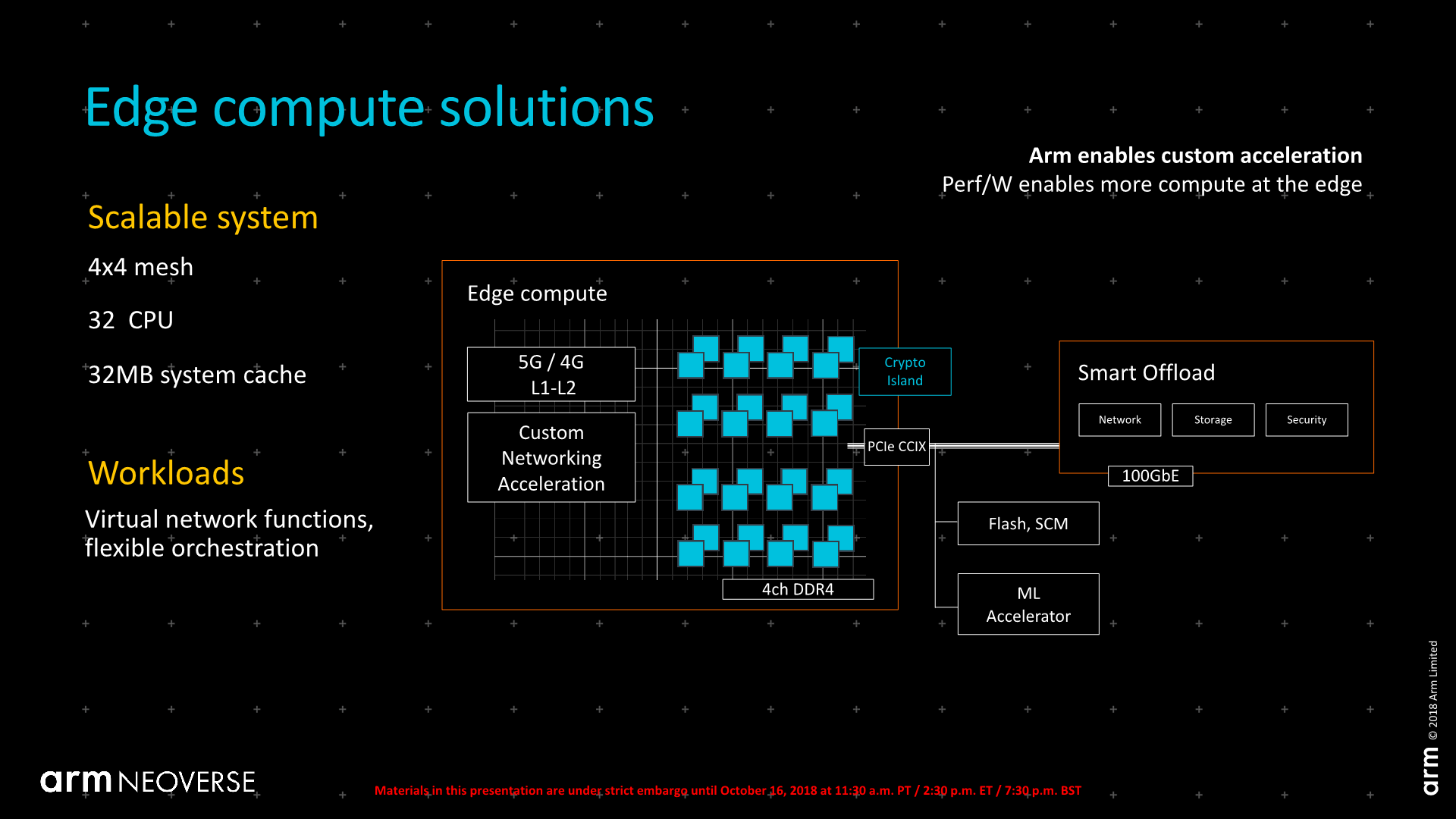
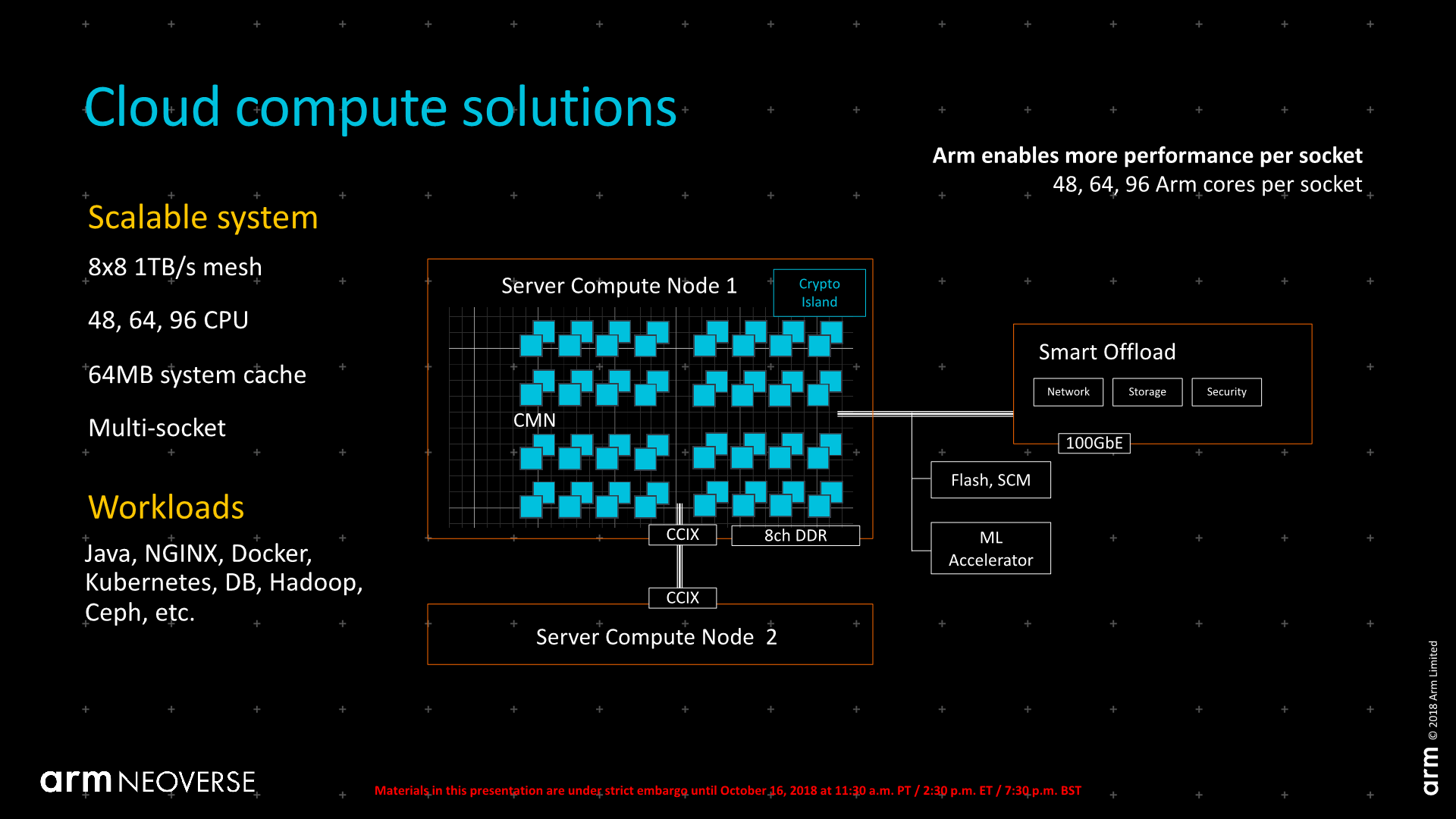
Arm went on to discuss more the various scaling possibilities that vendors can achieve by using Arm’s IP, varying from more simple configurations in edge devices up to very wide implementations for server CPUs, advertising the possibility of 48, 64 or 96 cores per socket in the maximum configuration.
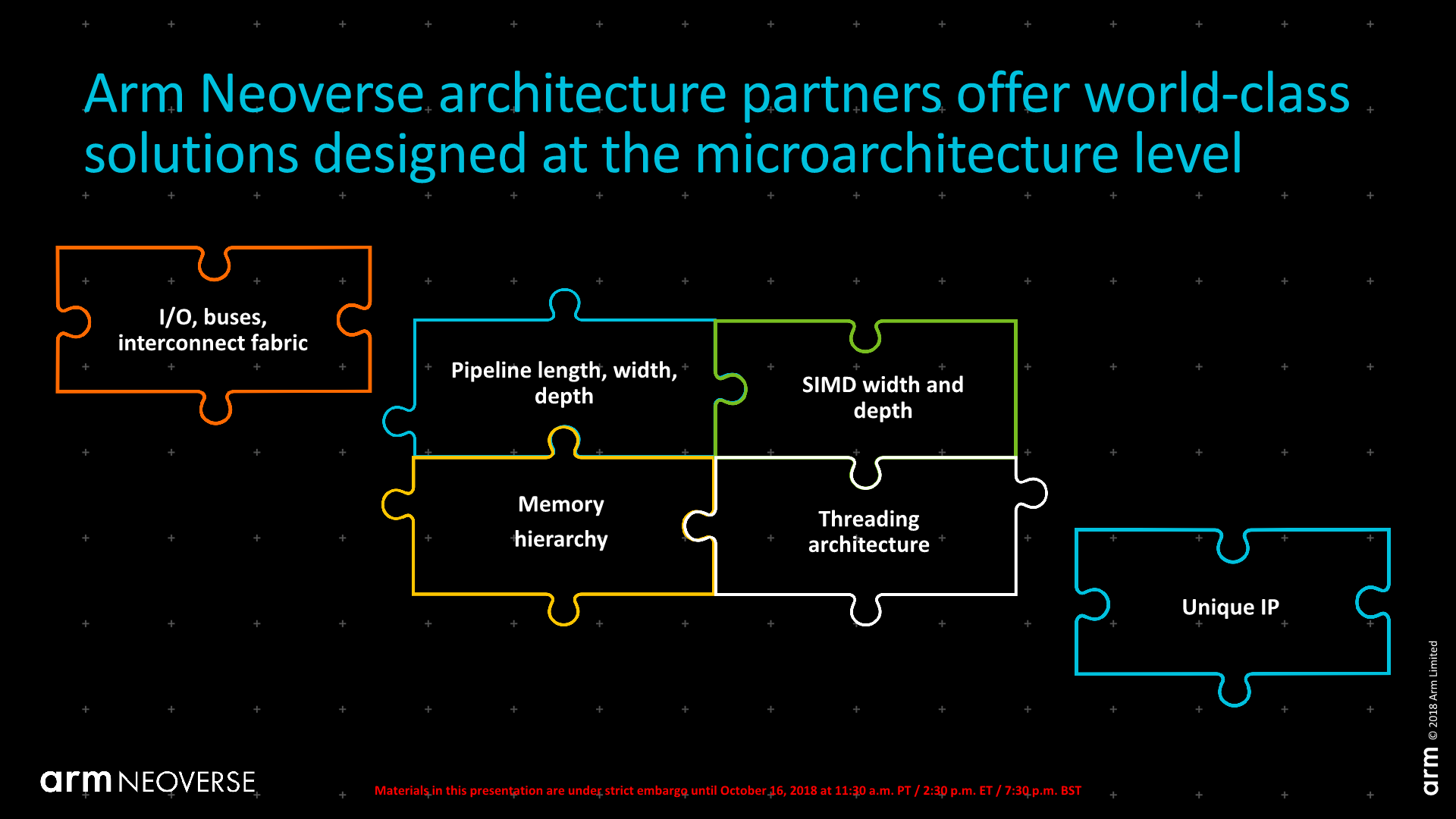
The one slide that really caught my eye and Arm notoriously went over quick was in regards to the offering for architecture partners. Here Arm wants to again communicate that it’s able to provide customised IP on demand, and alter things such as the interfaces to the cores, their memory hierarchy as well as the SVE units’ width and depth. Among these items is also “threading architecture”. While I’m not keen on guessing Arm’s intents here, I do wonder if this means we’ll be seeing SMT implemented in Arm’s Neoverse IPs?
While today’s announcement didn’t have any major technical unveiling, it does put to rest the question how Arm is going to name its new server cores, as well as publicly acknowledging roadmap names and goals for the coming years. Arm promised more details and announcements at TechCon – and we’ll be sure to report on the happenings in the comings days.








5 Comments
View All Comments
r3loaded - Tuesday, October 16, 2018 - link
> Among these items is also “threading architecture”. While I’m not keen on guessing Arm’s intents here, I do wonder if this means we’ll be seeing SMT implemented in Arm’s Neoverse IPs?Yes.
ztrouy - Wednesday, October 17, 2018 - link
Honestly, I would love to see SMT become a standard feature of the Cortex IP line. I know that it would probably take a few generations for it to trickle down to the lower end. However, I still would hope that would push ARM and other chip designers to focus on creating larger, more powerful cores more similar to Apples, even if they couldn't reach quite the girth of apple's silicon.ZolaIII - Wednesday, October 17, 2018 - link
Why shouldn't they? After all Apple uses the same ARM instruction set & all do it have wider OoO core's for a mainstream user product's it's also two steps behind reference ARM design (predictor & task scheduler). An usual price for a costume design. If you trow in available server grade ARM designs Apple ain't leading in anything. If ARM starts introducing IP server designs & if those are presumably good one's it will cut those steps behind for costume core's. I don't believe ARM is about to go the SMT path which cortex A76 unique design approach approves. At one point the vertical SMT makes sense as it's much less costly strategy then SMT, large TBL tables or cache multiplication. Same way the Imagination Technologies did & came to same conclusion. One thing is clear the wider the core is it's harder to optimal feed it & this is especially even more the case for ultra wide SIMD extension blocks.edzieba - Wednesday, October 17, 2018 - link
With a heterogenous core layout now the de-facto standard for ARM, is SMT even desirable? SMT helps you utilise cores that are partially idle and shedding power for no performance benefit, but on ARM the solution to this is already to switch to a smaller, more efficient core to match the current workload. SMT is great when you have a lot of workload and are limited by how big you can make your die, but on mobile (ARMs bread and butter, despite multiple abortive attempts to break into the datacentre) you don't really have those big chunks of high workload to chew through.jdiamond - Thursday, February 21, 2019 - link
SMT operates at a much lower scale than you imply: When a core has a lot of functional units, a single instruction stream may not have enough instruction level parallelism to leverage all of them every cycle, leading to lots of empty instruction slots. SMT effectively gives a massive boost to the ILP created by a large out of order instruction window, by providing multiple completely independent instruction streams to utilize all those lost ALU slots. SMT is particularly helpful with covering the latency of cache misses when the OO window is insufficient. SMT is the more efficient choice when (1) your application actually has parallel threads, and (2) your core has the potential to issue many instructions per cycle.