AMD Opteron Coverage - Part 1: Intro to Opteron/K8 Architecture
by Anand Lal Shimpi on April 23, 2003 3:03 AM EST- Posted in
- CPUs
Go Deep
At this point, AMD had two options - go wide, or do deep. To go wide would mean to increase the number of execution units in the core, which would make sense if the K8 were to be an enterprise-only core as a wider core is better suited for massively parallel applications. However, the desire to make K8 a desktop solution and the resulting desire for higher clock speeds led AMD to go deep, that is, deepen the pipeline.
Regardless of what route AMD chose, one thing was for sure; in order to take advantage of the fact that more instructions would be coming down the pipe between branch mispredicts, they'd need a larger buffer to store these instructions in. The buffer that keeps instructions "in flight" is known as the scheduling window, and if you look back up at the increase in the number of entries for the integer scheduler you'll now understand why AMD made the change; more instructions in flight, requires more entries in the schedulers to keep up. We can only assume that the floating point scheduling window was already large enough that it did not need any expansion; keep in mind that most branch instructions occur in integer code, which would help explain why the floating point scheduler remains unchanged from the K7 despite the more accurate branch predictor.
|
AMD
Integer Pipeline Comparison
|
||
|
Clock
Cycle
|
K7
Architecture
|
K8
Architecture
|
| 1 |
Fetch
|
Fetch
1
|
| 2 |
Scan
|
Fetch
2
|
| 3 |
Align
1
|
Pick
|
| 4 |
Align
2
|
Decode
1
|
| 5 |
EDEC
|
Decode
2
|
| 6 |
IDEQ/Rename
|
Pack
|
| 7 |
Schedule
|
Pack/Decode
|
| 8 |
AGU/ALU
|
Dispatch
|
| 9 |
L1
Address Generation
|
Schedule
|
| 10 |
Data
Cache
|
AGU/ALU
|
| 11 |
Data
Cache 1
|
|
| 12 |
Data
Cache 2
|
|
So AMD opened up the integer scheduling window, and gave the K8 a couple more pipeline stages to play with. The purpose of these additional stages, as we mentioned before, is solely to allow the K8 core to reach higher clock speeds. The more pipeline stages you have, the less work is done per clock and thus the higher you're able to clock your CPU; this is the reason the 20-stage Xeon is currently at speeds of 3GHz, compared to the 12-stage Opteron which is debuting at 1.8GHz.
The difference in pipeline architectures is what makes a clock-for-clock comparison between the Xeon and Opteron invalid (much like the Pentium 4 to Athlon XP comparison was invalid on a clock-for-clock basis). The Xeon's architecture allows it to reach high clock speeds at the expense of doing less work per clock cycle, the appropriate comparison ends up being one of cost and real-world performance, not one of clock speed.
The K8 caches are identical to the K7 caches, although with slightly lower latencies and higher bandwidth as you can see from the following performance comparisons:
|
|
|
|
The final microarchitectural changes (before we get into the two big ones) to the K7 core come in the form of what AMD likes to call the K8's "Large Workload TLBs."
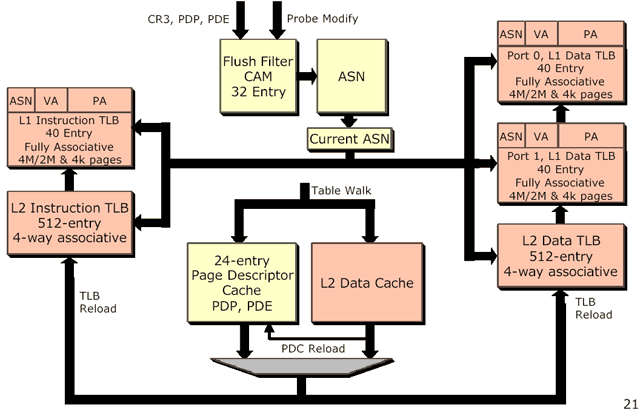
The number of entries in the K8's Translation Lookaside Buffers has been increased in order to cope with the usage model the Opteron will most likely find itself in - servers with very large memory requirements. The performance impact of the increase in TLB entries on the desktop will most likely be minimal as we noticed when AMD first increased TLB sizes with the K7 Palomino core; 3D rendering applications did receive a somewhat reasonable performance boost if you recall.








1 Comments
View All Comments
skunklet - Thursday, June 30, 2005 - link
YEAH