Quick Note: Intel “Knights Landing” Xeon Phi & Omni-Path 100 @ ISC 2015
by Ryan Smith on July 13, 2015 6:30 PM EST
Taking place this week in Frankfurt, Germany is the 2015 International Supercomputing Conference. One of the two major supercomputing conferences of the year, ISC tends to be the venue of choice for major high performance computing announcements for the second half of the year and is where the summer Top 500 supercomputer list is unveiled.
In any case, Intel sends word over that they are at ISC 2015 showing off the “Knights Landing” Xeon Phi, which is ramping up for commercial deployment later this year. Intel unveiled a number of details about Knights Landing at last year’s ISC, where it was announced that the second-generation Xeon Phi would be based on Intel’s Silvermont cores (replacing the P54C cores in Knights Corner) and built on Intel’s 14nm process. Furthermore Knights Landing would also include up to 16GB of on-chip Multi-Channel DRAM (MCDRAM), an ultra-wide stacked memory standard based around Hybrid Memory Cube.

Having already revealed the major architecture details in the last year, at this year’s show Intel is confirming that Knights Landing remains on schedule for its commercial launch later this year. This interestingly enough will make Knights Landing the second processor to ship this year with an ultra-wide stacked memory technology, after AMD’s Fiji GPU, indicating how quickly the technology is being adopted by processor manufacturers. More importantly for Intel of course, this will be the first such product to be targeted specifically at HPC applications.
Meanwhile after having previously announced that the design would include up to 72 cores - but not committing at the time to shipping a full 72 core part due to potential yield issues - Intel is now confirming that one or more 72 core SKUs will be available. This indicates that Knights Landing is yielding well enough to ship fully enabled, something the current Knights Corner never achieved (only shipping with up to 61 of 62 cores enabled). Notably this also narrows down the expected clockspeeds for the top Knights Landing SKU; with 72 cores capable of processing 32 FP64 FLOPs/core (thanks to 2 AVX-512 vector units per core), Intel needs to hit 1.3GHz to reach their 3 TFLOPs projection.
Moving on, Knights Landing’s partner interconnect technology, Omni-Path, is also ramping up for commercial deployment. After going through a few naming variants, Intel has settled on the Omni-Path Fabric 100 series, to distinguish it from planned future iterations of the technology. We won’t spend too much on this, but it goes without saying that Intel is looking to move to a vertically integrated ecosystem and capture the slice of HPC revenue currently spent on networking with Infiniband and other solutions.

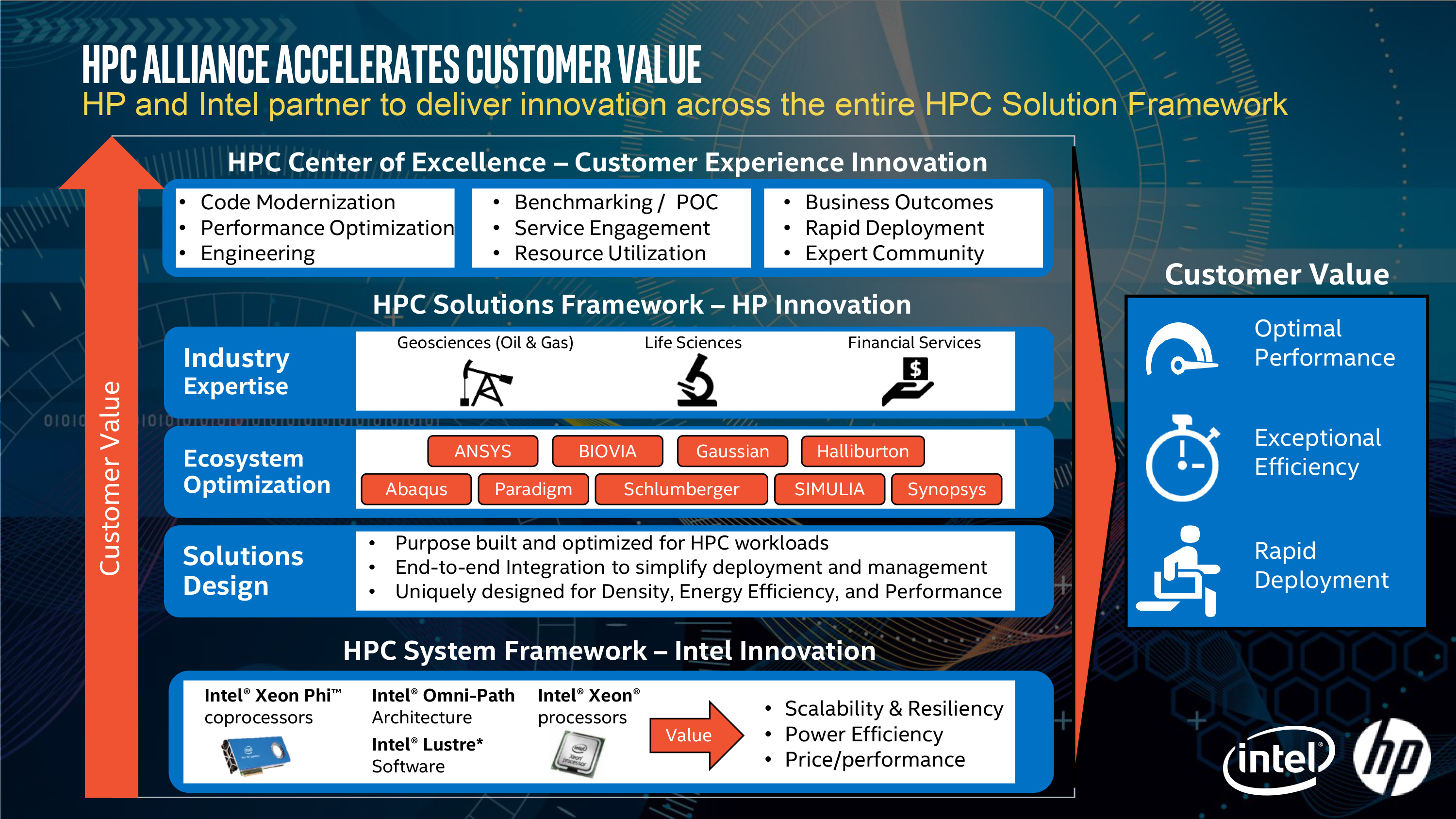
Finally, in order to develop that vertically integrated ecosystem, Intel is announcing that they have teamed up with HP to build servers around Intel’s suite of HPC technologies (or as Intel calls it, their Scalable System Framework). HP will be releasing a series of systems under the company’s Apollo brand of HPC servers that will integrate Knights Landing, Omni-Path 100, and Intel’s software stack. For Intel the Apollo HPC systems serve two purposes: to demonstrate the capabilities of their ecosystem and the value of their first-generation networking fabric, and of course to get complete systems on the market and into the hands of HPC customers.
Source: Intel








53 Comments
View All Comments
Refuge - Friday, July 17, 2015 - link
+1 good sir! :DtuxRoller - Monday, July 13, 2015 - link
Maybe, but I'm told that xeon phi's maximum gflops is more easily achievable than on current gpgpus.Obviously, hsa should be bringing gpgpus closer to cpu's in terms of context-switching and minimum scheduable elements, but they're not there yet.
testbug00 - Monday, July 13, 2015 - link
Getting 90% of 3TFLOP versus getting 70% of 6-8+TF... I'll take the 70%.It is a lot more interesting if FP64, where the only current GPU that challenges are professional Hawaii cards. Although, even at that point, Intel with a 100% utlization (I believe their FP64 rate is 1/2 FP32) for about 1500GFLOPs relies on AMD's cards failing to hit over 55%.
Of course, there are applications where the ability to have more CPU-like performance will serve better than a more GPU like performance.
testbug00 - Monday, July 13, 2015 - link
the 90% and 70% I made up. Safe to say, I'm guessing the difference isn't much larger than that. Also, talking to someone who went to a workshop, that was not the impression that fully utilizing it was not as easy a GPUs, but, that can change rapidly depending on software.cmikeh2 - Tuesday, July 14, 2015 - link
Xeon Phi does get 3 TFLOPS on FP64. Each core has two AVX512 vector units per core, so with each capable of an FMA for each of the eight FP64 you get 32 FLOPs per core per cycle. 72 cores a chip gets you 2304 FLOPs per cycle total. At the estimated frequency of 1.3 GHz that comes out to be 2.995 TFLOPS of FP64.SaberKOG91 - Tuesday, July 14, 2015 - link
That's peak throughput though. It will drop dramatically as the number of non FMAC instructions increases. Unless you are doing a lot of matrix operations or DSP algorithms, it will be hard to realize even half of that. For example:90/10 split => 95% efficiency
80/20 split => 90%
70/30 split => 85%
50/50 split => 75%
20/80 split => 60% efficiency
Of course it is impressive that the throughput is so high in the first place, but the FirePro S9170 was just launched with 2.62 TFLOP/s of FP64 at no more than 275W. And all my OpenCL code will just run faster than it used to. No porting necessary.
Ian Cutress - Tuesday, July 14, 2015 - link
There's also a register benefit with Xeon Phi, allowing for much larger per-thread kernel executions with data in-flight. On GPGPU it's a little restrictive in that sense, and you have to make threads lightweight. Xeon Phi threads can be super branchy and still be efficient.MrSpadge - Tuesday, July 14, 2015 - link
This opens up the door for algorithms which could not yet be accalerated by GPUs at all. That's what Intel is targeting: more flexibility, new algorithms and binary compatibility. Those are things the current GPUs can't do, despite matching the raw horse power (Hawaii).CajunArson - Tuesday, July 14, 2015 - link
Uh... I'd take 100% of 100TFlops myself since your numbers are completely made-up and I can make better made-up numbers.In the real-world, 3 Tflops of double precision is what Nvidia is hoping to achieve in 2016 with Pascal and AMD isn't even participating in this market. That's not even taking into account the benefits of having real CPU hardware in your parallel processor instead of having to rely on shaders that were intended to play video games and were re-tasked for the HPC world.
Don't let marketing nonsense from AMD about mythical "8Tflop" compute performance on the Furry fool you. First of all, that's *single precision* and these cards are meant for real computers doing double precision workloads, not glorified video game systems. At DP a Knights Landing part is between 5 to 6 times faster than the Furry-X that only clocks in at about 0.5 TFlops DP.
MrSpadge - Tuesday, July 14, 2015 - link
To be fair, AMDs Hawaii with 1/2 FP64 rate is actually participating at 2.6 DP GFlops peak performance in the currently fasted FirePro.