What We've Been Waiting For: Testing OpenCL Accelerated Handbrake with AMD's Trinity
by Anand Lal Shimpi on May 15, 2012 1:23 PM ESTAMD, and NVIDIA before it, has been trying to convince us of the usefulness of its GPUs for general purpose applications for years now. For a while it seemed as if video transcoding would be the killer application for GPUs, that was until Intel's Quick Sync showed up last year.
With Trinity, AMD has an answer to Quick Sync with its integrated VCE, however the performance is hardly as similar as the concept. In applications that take advantage of both Quick Sync and VCE, the Intel solution is considerably faster. While this first implementation of working VCE is better than x86 based transcoding on AMD's APUs, it still needs work:

Quick Sync's performance didn't move all users to Sandy/Ivy Bridge based video transcoding. One of its biggest limitations is the lack of good software support for the standard. We use applications like Arcsoft's Media Converter 7.5 and Cyber Link's Media Espresso 6.5 not because we want to, but because they are among the few transcoding applications that support Quick Sync. What we'd really like to see is support for Quick Sync in x264 or through an application like Handbrake.
The open source community thus far hasn't been very interested in supporting Intel's proprietary technologies. As a result, Quick Sync remains unused by the applications we want to use for video transcoding.
In our conclusion to this morning's Trinity review, we wrote that AMD's portfolio of GPU accelerated consumer applications is stronger now than it has ever been before. Photoshop CS6, GIMP, Media Converter/Media Espresso and WinZip 16.5 for the most part aren't a list of hardly used applications. These are big names that everyone is familiar, that many have actual seat time with. Now there's always the debate of whether or not the things you do with these applications are actually GPU accelerated, but AMD is at least targeting the right apps with its GPU compute efforts.
The list is actually a bit more impressive than what we've published thus far. Several weeks ago AMD dropped a bombshell: x264 and Handbrake would both feature GPU acceleration, largely via OpenCL, in the near future. I begged for an early build of both of them and eventually got just that. What you see below may look like a standard Handbrake screenshot, but it's actually a look at an early build of the OpenCL accelerated version of Handbrake:
As I mentioned before, the application isn't ready for prime time yet. The version I have is currently 32-bit only and it doesn't allow you to manually enable/disable GPU acceleration. Instead, to compare the x86 and OpenCL paths we have to run the beta Handbrake release against the latest publicly available version of the software.
GPU acceleration in Handbrake comes via three avenues: DXVA support for GPU accelerated video decode, OpenCL/GPU acceleration for video scaling and color space conversion, and OpenCL/GPU acceleration of the lookahead function of the x264 encoding process.
Video decode is the lowest hanging fruit to improving video transcode performance, and by using the DXVA API Handbrake can leverage the hardware video decode engine (UVD) on Trinity as well as its counterpart in Intel's Sandy/Ivy Bridge.
The scaling, color conversion and lookahead functions of the encode process are similarly obvious candidates for offloading to the GPU. The latter in particular is already data parallel and runs in its own thread, making it a logical fit for the GPU. The lookahead function determines how many frames the encoder should look ahead in time in the input stream to achieve better image quality. Remember that video encoding is fundamentally a task of figuring out which parts of frames remain unchanged over time and compressing that redundant data.
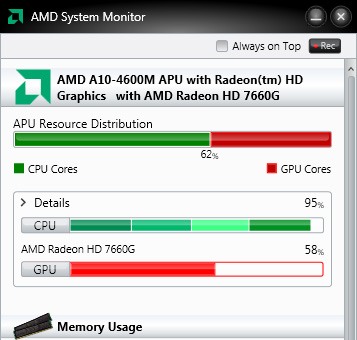
GPU usage during transcode in the OpenCL enhanced version of Handbrake
We're still working on a lot of performance/quality characterization of Handbrake, but to quickly illustrate what it can do we performed a simple transcode of a 1080p MPEG-2 source using Handbrake's High Profile defaults and a 720p output resolution.
The OpenCL accelerated Handbrake build worked on Sandy Bridge, Ivy Bridge as well as the AMD APUs, although obviously Sandy Bridge saw no benefit from the OpenCL optimizations. All platforms saw speedups however, implying that Intel benefitted handsomely from the DXVA decode work. We ran both 32-bit x86 and 32-bit GPU accelerated results on all platforms. The results are below:

*SNB's GPU doesn't support OpenCL, video decode should be GPU accelerated, all OpenCL work is handled by the CPU
While video transcoding is significantly slower on Trinity compared to Intel's Sandy Bridge on the traditional x86 path, the OpenCL version of Handbrake narrows the gap considerably. A quad-core Sandy Bridge goes from being 73% faster down to 7% faster than Trinity. Ivy Bridge on the other hand goes from being 2.15x the speed of Trinity to a smaller but still pronounced 29.6% lead. Image quality appeared to be comparable between all OpenCL outputs, although we did get higher bitrate files from the x86 transcode path. The bottom line is that AMD goes from a position of not really competitive, to easily holding its own against similarly priced Intel parts.
This truly is the holy grail for what AMD is hoping to deliver with heterogeneous compute in the short term. The Sandy Bridge comparison is particularly telling. What once was a significant performance advantage for Intel, shrinks to something unnoticeable. If AMD could achieve similar gains in other key applications, I think more users would be just fine in ignoring the CPU deficit and would treat Trinity as a balanced alternative to Intel. The Ivy Bridge gap is still more significant but it's also a much more expensive chip, and likely won't appear at the same price points as AMD's A10 for a while.
We're working on even more examples of where AMD's work in enabling OpenCL accelerated applications are changing the balance of power in the desktop. Handbrake is simply the one we were most excited about. It will still be a little while before there are public betas of x264 and Handbrake, but it's at least something we can now look forward to.








60 Comments
View All Comments
CeriseCogburn - Wednesday, May 23, 2012 - link
ROFL - amd doesn't have this ready ? Why imagine that, how so terribly unusual for them.... hahahhahaWell,what about the 2 compute benches 79xx won against 680 who won 3?
If 79xx can pull out this "hopefully coming" test they can even up the compute bench scoring... and can be one step short even then of showing more compute performance instead of dead paperweighted claims.
thefoodaddy - Tuesday, May 15, 2012 - link
oh boy oh boy oh boy FINALLY.CeriseCogburn - Wednesday, May 23, 2012 - link
"It's not ready for prime time".... so finally is still waiting.Khato - Tuesday, May 15, 2012 - link
As per the subject, are we certain that the IVB sample actually was using GPU OpenCL acceleration? I ask because IVB is showing roughly the same 1FPS per core increase going from the public to beta Handbrake as the two SNB samples. That implies that the gains are due only to the DXVA decode acceleration just as on SNB. Well, either that or IVB's GPU OpenCL acceleration potential is non-existent, which really doesn't seem right.Khato - Tuesday, May 15, 2012 - link
And much as I hate replying to myself... Looks like I may have found an answer to my question. Apparently the IVB GPU OpenCL implementation is rather finicky - http://software.intel.com/en-us/forums/showthread....name99 - Tuesday, May 15, 2012 - link
"The open source community thus far hasn't been very interested in supporting Intel's proprietary technologies. As a result, Quick Sync remains unused by the applications we want to use for video transcoding."Is this an honest description of the situation?
I thought the problem was more some combination of
- Intel doesn't provide good docs about how to use it AND
- it's privileged so you have to go through the OS to use it --- which means you're gated by what the OS is willing or not willing to provide you.
TerdFerguson - Tuesday, May 15, 2012 - link
It's a fair assessment of the situation. The engineer who devised quicksync introduced himself to the x264 team in a public forum and they acted like jerks instead of recognizing the gift dropped in their laps.Manabu - Wednesday, May 16, 2012 - link
That is not the full history. Latter, Dark Shikari, one of the main developers of x264, said:"Since the original Intel failure, I have learned quite a bit more about the lower-level details, and I'd quite love to explain more, but unfortunately I am now deep into NDA territory. If this means people are going to blame x264 for QuickSync's failings, well, unfortunately there's not much I can legally do about it anymore."
> does that mean you are now technically able to allow some parts of x264
> encoding to be done by quicksync? If so is this support going to be added?
"Maybe yes, probably not. There are some pretty devastating technical limitations."
Source: http://forum.doom9.org/showthread.php?p=1511469#po...
CeriseCogburn - Wednesday, May 23, 2012 - link
Same source: " Originally Posted by Dark Shikari View PostIf you set the bitrate sufficiently high, the quality difference between encoders becomes negligible
That's the whole point. So if the quality differences are consistently negligible, why wouldn't you favor the encoder that is magnitudes faster?
Quote:
Originally Posted by Dark Shikari View Post
Twice as fast at what settings? You cannot validly claim "X is faster than Y" if you told Y to go slowly.
Please refer to the testing methodology of the AnandTech article on the first page of this thread. You may also refer to the TomsHardware benchmark comparisons. Although quality isn't discussed with that article you can see a 3x speed-up against CUDA-based encodes, and 6x against software-only encodes using a commercial product, MediaExpresso. Another TomsHardware benchmark of Quick Sync against the AMD Llano APU can be found here. Outside of the obvious hardware differences, we're talking 46 seconds versus 3:13 minutes.
Not trying to begin another quality vs. performance argument, so I'll just leave it at that to let you deal with the facts on your own."
LOL - nice try
SikSlayer - Tuesday, May 15, 2012 - link
Does Handbrake OpenCL acceration work for Nvidia GPU users?