Qualcomm's New Snapdragon S4: MSM8960 & Krait Architecture Explored
by Brian Klug & Anand Lal Shimpi on October 7, 2011 12:35 PM EST- Posted in
- Smartphones
- Snapdragon
- Arm
- Qualcomm
- Krait
- MDP
- Mobile
- SoCs
Cache & Memory Hierarchy
Qualcomm has a three level exclusive cache hierarchy in Krait. The lower two levels are private per core, while the third level is shared among all cores. Qualcomm calls these caches L0, L1 and L2.
Each Krait core has an 8KB L0 cache (4KB instruction + 4KB data cache). The L0 cache is direct mapped and accessible in a single cycle. Qualcomm claims an 85% hit rate in this level 0 cache, which helps save power by not firing up the larger L1 cache. The hierarchy is exclusive so L0 data isn't necessarily duplicated in L1.
Each core also has a 32KB L1 cache (16KB instruction + 16KB data). The L1 4-way set associative and can also be accessed in a single cycle. There's no way prediction at work here. With 1 cycle latency to both L0 and L1, the primary advantage here is power.
| Krait Cache Architecture | |||||
| Size | Architecture | Frequency | |||
| L0 | 4KB + 4KB | Direct Mapped | Core | ||
| L1 | 16KB + 16KB | 4-way set associative | Core | ||
| L2 | 1MB (dual core) or 2MB (quad core) | 8-way set associative | 1.3GHz max | ||
The L2 cache is shared among all cores. In dual-core designs the L2 cache is sized at 1MB (up from 512KB in Scorpion), while quad-core Krait SoCs will have a 2MB L2. Krait's L2 cache is 8-way set associative.
While the L0 and L1 caches operate at core frequency and are on the same voltage plane as their associated core, the L2 cache is separate. To save power the L2 cache runs at its own frequency (up to 1.3GHz depending on the currently requested performance level). The L2 cache is on its own power plane and can be power gated if necessary.
Although Scorpion featured a dual-channel LPDDR2 memory controller, in a PoP configuration only one channel was available to any stacked DRAM. In order to get access to both 32-bit memory channels the OEM had to implement a DRAM on-package as well as an external DRAM on the PCB. Memory requests could be interleaved between the two DRAM, however Qualcomm seemed to prefer load balancing between the two with CPU/GPU accesses being directed to the lower latency PoP DRAM. Very few OEMs seemed to populate both channels and thus Scorpion based designs were effectively single-channel offerings.
Krait removes this limitation and now OEMs can utilize both memory channels in a PoP configuration (simply put two 32-bit DRAM die on the PoP stack) or in an external configuration. The split PoP/external DRAM organization is no longer supported. This change will hopefully mean we'll see more dual-channel Krait designs than we saw with Scorpion, which will in turn improve performance.
Process Technology and Clock Speeds
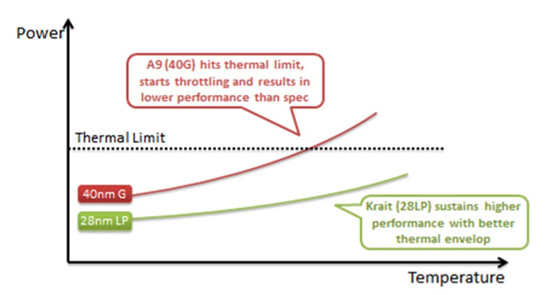
Krait will be the world's first smartphone CPU built on a 28nm process. Qualcomm is working with both TSMC and Global Foundries, although TSMC will produce the first chips. Krait will be built, at first, on TSMC's standard 28nm LP process. According to Qualcomm there's less risk associated with TSMC's non-HKMG process. Qualcomm was quick to point out that the entire MSM8960 SoC is built on a 28nm LP process compared to NVIDIA's 40nm LPG design in Kal-El. From Qualcomm's perspective, 40nm G transistors are only useful at reducing leakage at high temperatures but for the majority of the time a homogeneous LP design makes more sense.
Just like Scorpion, Krait places each core on its own voltage plane driven at its own clock frequency. Cores can be clocked independently of one another, which Qualcomm insists gives it a power advantage in many workloads.
The first implementation of Krait will be in a dual-core 1.5GHz MSM8960, however a second revision of the silicon will be introduced next year that increases clock speed to 1.7 - 2.0GHz. Qualcomm claims that at the same 1.05V core voltage, Krait can run at 1.7GHz vs. 1.55GHz for Scorpion. At these two clock speeds and at the same voltage, Qualcomm tells us that Krait consumes 265mW of power vs. 432mW running an undisclosed workload. Although it should be possible to draw more power than Scorpion under load, Krait should hopefully be able to improve overall power efficiency by completing tasks quicker and thus dropping down to idle faster than its predecessor. Smartphone and tablet battery life should remain the same at worst and improve at best, as a result.








108 Comments
View All Comments
metafor - Friday, October 7, 2011 - link
The SGX540 in the OMAP4460 is clocked significantly higher than (something TI is great at). So, while it isn't a powerhouse compared to Exynos or A5, it's more than sufficient. Google has never traditionally been top-of-the-line in terms of processors with their Nexus series. So it isn't out of the question they wouldn't be this time around either.dagamer34 - Saturday, October 8, 2011 - link
Technically, the Hummingbird SoC used in the Nexus S was top of the line at the time it was released (although it was eclipsed by dual-coe phones after 1-2 months). Also the Nexus One was the first major phone I can remember that had 512MB of RAM.However, it should be said that Google doesn't think about getting the best SoCs available for their product, but instead seeks to get the best deal on it's components from bidding against vendors. It's very possible that Samsung knows they had the most powerful SoC outside of the A5 and wanted Google to pay it for the value it would provide. Google instead apparently went with TI, likely because TI is selling it's chips cheaper in order to be the reference platform for Ice Cream Sandwich.
DanD85 - Friday, October 7, 2011 - link
Funny I saw Adreno 225 having 8 SIMDS and 5 MADS per SIMDS that should be equal to 40 total MADS right? Why it's 80? Am I missing sth?cptcolo - Friday, October 7, 2011 - link
Looking at the chart on "The Adreno 225 GPU" an comparing to the frame rates in the iPad 2 review (http://www.anandtech.com/show/4216/apple-ipad-2-gp... It looks like the PowerVR SGX543MP2 in the iPhone 4S will be about 33% faster. This is a very approximate estimate.cptcolo - Friday, October 7, 2011 - link
"Qualcomm claims that MSM8960 will be able to outperform Apple's A5 in GLBenchmark 2.x at qHD resolutions. We'll have to wait until we have shipping devices in hand to really put that claim to the test, but if true it's good news for Krait as the A5 continues to be the high end benchmark for mobile GPU performance."ssvb - Friday, October 7, 2011 - link
Please correct your CPU features comparison table (and in the previous articles too). ARM11 has a *pipelined* VFP, which actually makes it a lot faster than Cortex-A8 for double precision floating point workloads. You can have a look at the instruction cycle timings to get a better idea:ARM11 VFP - http://infocenter.arm.com/help/topic/com.arm.doc.d...
Cortex-A8 VFP - http://infocenter.arm.com/help/topic/com.arm.doc.d...
Thanks.
Anand Lal Shimpi - Friday, October 7, 2011 - link
Thank you! Fixed :)Take care,
Anand
icrf - Friday, October 7, 2011 - link
An ARM Cortext A9 has an 8 stage pipeline, not 9: http://www.arm.com/files/pdf/ARMCortexA-9Processor...Anand Lal Shimpi - Friday, October 7, 2011 - link
Thanks :)Take care,
Anand
Blaster1618 - Friday, October 7, 2011 - link
Maybe a noob, but I did not know that L0 memory could operate at GHz clock rate (5-10 times that of SD Ram clock rate. Good stuff, keep it coming. B-)