The Qualcomm Snapdragon X Architecture Deep Dive: Getting To Know Oryon and Adreno X1
by Ryan Smith on June 13, 2024 9:00 AM EST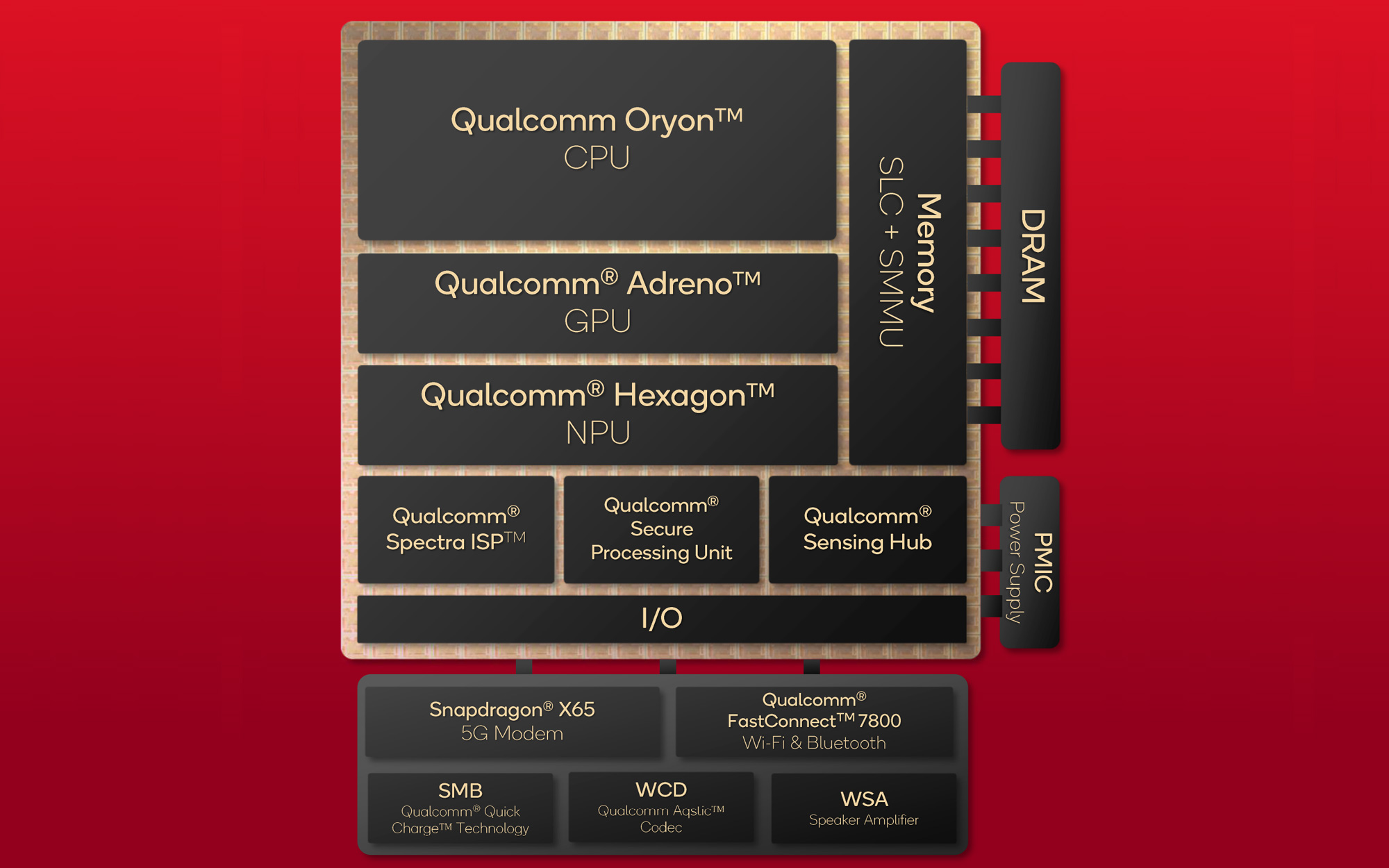
The curtains are drawn and it’s almost showtime for Qualcomm and its Snapdragon X SoC team. After first detailing the SoC nearly 8 months ago at the company’s most recent Snapdragon Summit, and making numerous performance disclosures in the intervening months, the Snapdragon X Elite and Snapdragon X Plus launch is nearly upon us. The chips have already shipped to Qualcomm’s laptop partners, and the first laptops are set to ship next week.
In the last 8 months Qualcomm has made a lot of interesting claims for their high-performance Windows-on-Arm SoC – many of which will be put to the test in the coming weeks. But beyond all the performance claims and bluster amidst what is shaping up to be a highly competitive environment for PC CPUs, there’s an even more fundamental question about the Snapdragon X that we’ve been dying to get to: how does it work?
Ahead of next week’s launch, then, we’re finally getting the answer to that, as today Qualcomm is releasing their long-awaited architectural disclosure on the Snapdragon X SoC. This includes not only their new, custom Arm v8 “Oryon” CPU core, but also technical disclosures on their Adreno GPU, and the Hexagon NPU that backs their heavily-promoted AI capabilities. The company has made it clear in the past that the Snapdragon X is a serious, top-priority effort for the company – that they’re not just slapping together a Windows SoC from their existing IP blocks and calling it a day – so there’s a great deal of novel technology within the SoC.

And while we’re excited to look at it all, we’ll also be the first to admit that we’re the most excited to finally get to take a deep dive on Oryon, Qualcomm’s custom-built Arm CPU cores. The first new high-performance CPU design created from scratch in the last several years, the significance of Oryon cannot be overstated. Besides providing the basis of a new generation of Windows-on-Arm SoCs that Qualcomm hopes will vault them into contention in the Windows PC marketplace, Oryon will also be the basis of Qualcomm’s traditional Snapdragon mobile handset and tablet SoCs going forward.
So a great deal of the company’s hardware over the next few years is riding on this CPU architecture – and if all goes according to plan, there will be many more generations of Oryon to follow. One way or another, it’s going to set Qualcomm apart from its competitors in both the PC and mobile spaces, as it means Qualcomm is moving on from Arm’s reference designs, which by their very nature are accessible Qualcomm’s competition as well.
So without further ado, let’s dive in to Qualcomm’s Snapdragon X SoC architecture.
Setting The Stage: Elite, Plus, & Currently Announced SKUs
As a quick refresher, Qualcomm has announced 4 Snapdragon X SKUs thus far, all of which have been made available to device manufacturers for next week’s launch.
| Qualcomm Snapdragon X (Gen 1) Processors | |||||||
| AnandTech | CPU Cores | All Core Max Turbo | Two Core Max Turbo | GPU TFLOPS | NPU TOPS | Total Cache (MB) |
Memory |
| Snapdragon X Elite | |||||||
| X1E-84-100 | 12 | 3.8 GHz | 4.2 GHz | 4.6 | 45 | 42 | LPDDR5X-8448 |
| X1E-80-100 | 12 | 3.4 GHz | 4.0 GHz | 3.8 | 45 | 42 | LPDDR5X-8448 |
| X1E-78-100 | 12 | 3.4 GHz | 3.4 GHz | 3.8 | 45 | 42 | LPDDR5X-8448 |
| Snapdragon X Plus | |||||||
| X1P-64-100 | 10 | 3.4 GHz | 3.4 GHz | 3.8 | 45 | 42 | LPDDR5X-8448 |
Three of these are “Elite” SKUs, which are defined by their inclusion of 12 CPU cores. Meanwhile Qualcomm is offering a single “Plus” SKU (thus far), which cuts that down to 10 CPU cores.
Officially, Qualcomm isn’t assigning any TDP ratings to these chip SKUs, as, in principle, any given SKU can be used across the entire spectrum of power levels. Need to fit in a top-tier chip in a fanless laptop? Just turn down the TDP to match your power/cooling capabilities. That said, to hit the highest clockspeed and performance targets of Qualcomm’s chips, a good bit of cooling and power delivery are required. And to that end we aren’t likely to see X1E-84-100 show up in fanless devices, for example, as its higher clockspeeds would largely be wasted by a lack of thermal headroom. This won’t stop lower-performance chips from being used in bigger devices as budget options, but the SKU table can also be considered as being roughly sorted by TDP.
And while not the subject of today’s disclosure, don’t be surprised to see further Snapdragon X chip SKUs further down the line. It’s become a poorly kept secret that Qualcomm has at least one further Snapdragon X die in development – a smaller die with presumably fewer CPU and GPU cores – which we expect would make up a more budget-focused set of SKUs farther down the line. But for now, Qualcomm is starting with their big silicon, and consequently their highest-performing options.

Even though the first Snapdragon X devices won’t reach consumers until next week, it’s already clear that, judging by OEM adoption, this is going to be Qualcomm’s most successful Windows-on-Arm SoC to date. The difference in adoption compared to the Snapdragon 8cx Gen 3 is practically night and day; Qualcomm’s PC partners have already developed over a dozen laptop models using the new chips, whereas the last 8cx could be found in all of two designs. So with Microsoft, Dell, HP, Lenovo, and others all producing Snapdragon X laptops, the Snapdragon X ecosystem is starting off much stronger than any Windows-on-Arm offering before it.
| Snapdragon Compute (Windows-on-Arm) Silicon | ||||
| AnandTech | Snapdragon X Elite | Snapdragon 8cx Gen 3 |
Snapdragon 8cx Gen 2 |
Snapdragon 8cx Gen 1 |
| Prime Cores | 12x Oryon 3.80 GHz 2C Turbo: 4.2GHz |
4x C-X1 3.00 GHz |
4 x C-A76 3.15 GHz |
4 x C-A76 2.84 GHz |
| Efficiency Cores | N/A | 4x C-A78 2.40 GHz |
4 x C-A55 1.80 GHz |
4 x C-A55 1.80 GHz |
| GPU | Adreno X1 | Adreno 8cx Gen 3 |
Adreno 690 | Adreno 680 |
| NPU | Hexagon 45 TOPS (INT8) |
Hexagon 8cx Gen 3 15 TOPS |
Hexagon 690 9 TOPS |
Hexagon 690 9 TOPS |
| Memory | 8 x 16-bit LPDDR5x-8448 135GB/sec |
8 x 16-bit LPDDR4x-4266 68.3 GB/sec |
8 x 16-bit LPDDR4x-4266 68.3 GB/sec |
8 x 16-bit LPDDR4x-4266 68.3 GB/sec |
| Wi-Fi | Wi-FI 7 + BE 5.4 (Discrete) |
Wi-Fi 6E + BT 5.1 | Wi-Fi 6 + BT 5.1 | Wi-Fi 5 + BT 5.0 |
| Modem | Snapdragon X65 (Discrete) |
Snapdragon X55/X62/X65 (Discrete) |
Snapdragon X55/X24 (Discrete) |
Snapdragon X24 (Discrete) |
| Process | TSMC N4 | Samsung 5LPE | TSMC N7 | TSMC N7 |
A big part of that, no doubt, comes down to the strength of Qualcomm’s architecture. The Snapdragon X packs what Qualcomm promotes as a vastly more powerful CPU than the Cortex-X1 core found on the most recent (circa 2022) 8cx chip, and it’s being built on a highly competitive process with TSMC’s N4 node. So if all of the stars are properly aligned, the Snapdragon X chips should be a massive step up for Qualcomm.
Meanwhile, there are two other pillars that are helping to hold up this launch. The first, of course, is AI, with the Snapdragon X being the first Copilot+ capable SoC for use with Windows. Requiring a 40+ TOPS NPU, the 45 TOPS Hexagon NPU in the Snapdragon X makes the SoC the first such chip to offer this much performance for neural network and other model inference. The second pillar, in turn, is power. Qualcomm is promising nothing short of amazing battery runtimes with their SoC, leveraging their years of experience producing mobile SoCs. And if they can deliver on it while also hitting their performance goals – allowing users to have their cake and eat it, too – then it will setup the Snapdragon X chips and the resulting laptops nicely.

Ultimately, Qualcomm is looking for their Apple Silicon moment – a repeat of the performance and battery life gains that Apple reaped when switching from Intel’s x86 chips to their own custom Arm-based Apple Silicon. And partner Microsoft, for their part, really, really wants a MacBook Air competitor in the PC ecosystem. It’s a tall order, not the least of which is because neither Intel or AMD have been sitting still over the past few years, but it’s not out of reach.

With that said, Qualcomm and the Windows-on-Arm ecosystem do face some obstacles that means Snapdragon X’s launch trajectory can never quite match Apple’s. Besides the obvious lack of a single unified party developing the hardware and software ecosystem (and all but shoving developers forward to produce software for it), Windows comes with the expectations of backwards compatibility and the legacy baggage that entails. Microsoft, for its part, has continued to work on their x86/x64 emulation layer, which now goes by the name Prism, and the Snapdragon X launch will be the first time it really gets put to the test. But even with years of Arm support within Windows, the software ecosystem is still slowly taking shape, so Snapdragon X will be more reliant on x86 emulation than Apple ever was. Windows and macOS are very distinct operating systems, both in terms of their histories and their owners’ development philosophies, and this is going to be especially apparent in the first years of the Snapdragon X’s lifetime.








51 Comments
View All Comments
Dolda2000 - Thursday, June 13, 2024 - link
I think we already knew there's no excuse for Apple not to support OpenCL and Vulkan. It's funny how Apple turned from being a supporter and inventor of open standards in the 2000s to "METAL ONLY" as soon as the iPhone became big. ReplyFWhitTrampoline - Thursday, June 13, 2024 - link
Imagine this, Just as Linux/MESA Gets a Proper and up to date to OpenCL(Rusticl: Implemented in the Rust Programming language) implementation to replace that way out of date and ignored for years MESA Clover OpenCL implementation, the Blender Foundation not a year or so before that goes on and Drops OpenCL as the GPU compute API in favor of CUDA/PTX and so there goes Radeon GPU compute API support over to ROCm/HIP that's needed to take that CUDA(PTX Intermediate Language representation) and convert/translate that to a form that can be executed on Radeon GPUs. And ROCm/HIP is never really been for consumer dGPUs or iGPUs and Polaris graphics was dropped from the ROCm/HIP support matrix years ago and Vega graphics is ready to be dropped as well! And so that's really fragmented the GPU compute API landscape there as Blender 3D 3.0/later editions only have native back end support for Nvidia CUDA/PTX and Apple Metal. So AMD has ROCm/HIP and Intel Has OneAPI that has similar functionality to AMD's ROCm/HIP. But Intel's got their OneAPI working good with Blender 3D for ARC dGPUs and ARC/Xe iGPUs on Linux as well while on Linux AMD's ROCm/HIP is not an easy thing for the non Linux neck-beard to get installed and working properly and only on a limited set of Linux Workstation Distros, unlike Intel's OneAPI and Level-0.But I'm on Zen+ and Vega 8/iGPU with a Polaris dGPU on one laptop and on Zen+ and Vega 11/iGPU on my ASRock X300 Desk Mini! And so my only hope at Blender 3D dGPU and iGPU accelerated cycles rendering is using Blender 2.93 and earlier editions that are legacy but still use OpenCL as the GPU compute API! But I'm still waiting for the Ubuntu folks to enable MESA/Rusticl instead of having that hidden behind some environment variable because that still unstable, and I'm downstream of Ubuntu on Linux Mint 21.3.
So I'm waiting for Mint 22 to get released to see if I will ever be able to get any Blender 3D iGPU or dGPU Accelerated Cycles rendering enabled because I do not want to use the fallback default and Blender's CPU accelerated Cycles rendering as that's just to slow and too stressful on the laptop and the Desk Mini(I'm using the ASRock provided cooler for that). Reply
name99 - Saturday, June 15, 2024 - link
"It's funny how Apple turned from being a supporter and inventor of open standards"You mean how Apple saw the small minds at other companies refuse to advance OpenCL and turn OpenGL into a godawful mess and concluded that trying to do things by committee was a complete waste of time?
And your solution for this is what? Every person who actually understands the issues is well aware of what a clusterfsck Vulkan is, eg https://xol.io/blah/death-to-shading-languages/
There's a reason the two GPU APIs/shading languages that don't suck (Metal and CUDA) both come from a single company, not a committee. Reply
Dante Verizon - Sunday, June 16, 2024 - link
The reason is that there are few great programmers. Replydan82 - Thursday, June 13, 2024 - link
Thanks for the write-up. I'm very much looking forward to the extra competition.I assume AVX2 emulation would be too slow with Neon. While it's possible to make it work, it would perform worse than SSE, which isn't what any application would expect. And the number of programs that outright require AVX2 are probably very few. I'm assuming Microsoft is waiting for SVE to appear on these chips before implementing AVX2 emulation. Reply
drajitshnew - Thursday, June 13, 2024 - link
Thanku Ryan and AT for a good CPU architecture update. It is a rare treat these days ReplyHulk - Thursday, June 13, 2024 - link
I think this might have been important if Lunar Lake wasn't around the corner. But after examining Lunar Lake I think this chip is overmatched. Good try though. ReplySIDtech - Friday, June 14, 2024 - link
😂😂😂😂 ReplyFWhitTrampoline - Thursday, June 13, 2024 - link
"Meanwhile the back-end is made from 6 render output units (ROPs), which can process 8 pixels per cycle each, for a total of 48 pixels/clock rendered. The render back-ends are plugged in to a local cache, as well as an important scratchpad memory that Qualcomm calls GMEM (more on this in a bit)."No that's 6 Render Back Ends of 8 ROPs each for a total of 48 ROPs and 16 more ROPs than either the Radeon 680M/780M(32 ROPs) or the Meteor Lake Xe-LPG iGPU that is 32 ROPs max. And so the G-Pixel Fill Rates there are on one slide and that is stated as 72 G-Pixels/S and really I'm impressed there with that raster performance!
Do you have the entire Slide Deck for this release as the slide I'm referencing with the Pixel fill rates as in another article or another website ? Reply
Ryan Smith - Thursday, June 13, 2024 - link
So the industry as a whole has always played a little fast and loose with how the term ROPs is thrown around. In all modern architectures, what you have is not X number of single units, but rather a smaller number of units that can render multiple pixels per cycle. In this case, 6 units, each of which can spit out 8 pixels.For historical reasons, we often just say ROPs = pixel count, and move on from there. It doesn't really harm anyone, even if's' not quite correct.
But since this is our first deep dive into the Adreno GPU architecture, I wanted to get this a bit more technically correct. Hence the wording I used in the article.
"Do you have the entire Slide Deck for this release as the slide I'm referencing with the Pixel fill rates as in another article or another website ? "
Yes, the complete slide deck is posted here: https://www.anandtech.com/Gallery/Album/9488 Reply