Google's Tensor inside of Pixel 6, Pixel 6 Pro: A Look into Performance & Efficiency
by Andrei Frumusanu on November 2, 2021 8:00 AM EST- Posted in
- Mobile
- Smartphones
- SoCs
- Pixel 6
- Pixel 6 Pro
- Google Tensor
Memory Subsystem & Latency
Usually, the first concern of a SoC design, is that it requires that it performs well in terms of its data fabric and properly giving its IP blocks access to the caches and DRAM of the system within good latency metrics, as latency, especially on the CPU side, is directly proportional to the end-result performance under many workloads.
The Google Tensor, is both similar, but different to the Exynos chips in this regard. Google does however fundamentally change how the internal fabric of the chip is set up in terms of various buses and interconnects, so we do expect some differences.
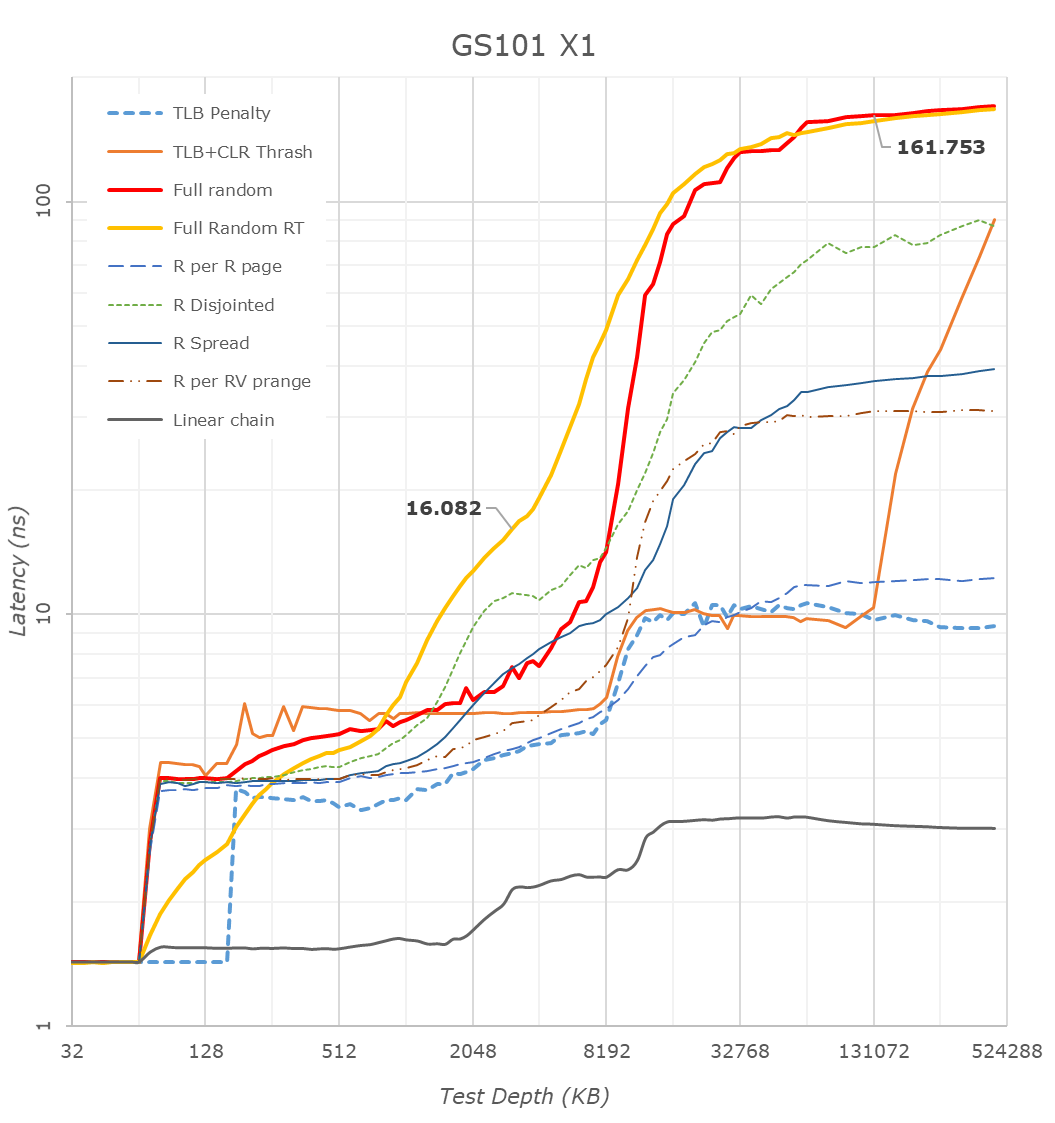
First off, we have to mention that many of the latency patterns here are still quite a broken due to the new Arm temporal prefetchers that were introduced with the Cortex-X1 and A78 series CPUs – please just pay attention to the orange “Full Random RT” curve which bypasses these.
There’s a couple of things to see here, let’s start at the CPU side, where we see the X1 cores of the Tensor chip being configured with 1MB of L2, which comes in contrast with the smaller 512KB of the Exynos 2100, but in line with what we see on the Snapdragon 888.
The second thing to note, is that it looks like the Tensor’s DRAM latency isn’t good, and showcases a considerable regression compared to the Exynos 2100, which in turn was quite worse off than the Snapdragon 888. While the measurements are correct in what they’re measuring, the problem is a bit more complex in the way that Google is operating the memory controllers on the Google Tensor. For the CPUs, Google is tying the MCs and DRAM speed based on performance counters of the CPUs and the actual workload IPC as well as memory stall % of the cores, which is different to the way Samsung runs things which are more transactional utilisation rate of the memory controllers. I’m not sure of the high memory latency figures of the CPUs are caused by this, or rather by simply having a higher latency fabric within the SoC as I wasn’t able to confirm the runtime operational frequencies of the memory during the tests on this unrooted device. However, it’s a topic which we’ll see brought up a few more times in the next few pages, especially on the CPU performance evaluation of things.
The Cortex-A76 view of things looks more normal in terms of latencies as things don’t get impacted by the temporal prefetchers, still, the latencies here are significantly higher than on competitor SoCs, on all patterns.
What I found weird, was that the L3 latencies of the Tensor SoC also look to be quite high, above that of the Exynos 2100 and Snapdragon 888 by quite a noticeable margin. I noted that one weird thing about the Tensor SoC, is that Google didn’t give the DSU and the L3 cache of the CPU cluster a dedicated clock plane, rather tying it to the frequency of the Cortex-A55 cores. The odd thing here is that, even if the X1 or A76 cores are under full load, the A55 cores as well as the L3 are still running at lower frequencies. The same scenario on the Exynos or Snapdragon chip would raise the frequency of the L3. This behaviour and aspect of the chip can be confirmed by running at dummy load on the Cortex-A55 cores in order to drive the L3 higher, which improves the figures on both the X1 and A76 cores.
The system level cache is visible in the latency hump starting at around 11-13MB (1MB L2 + 4MB L3 + 8MB SLC). I’m not showing it in the graphs here, but memory bandwidth on normal accesses on the Google chip is also slower than on the Exynos, but I think I do see more fabric bandwidth when doing things such as modifying individual cache lines – one of the reasons I think the SLC architecture is different than what’s on the Exynos 2100.
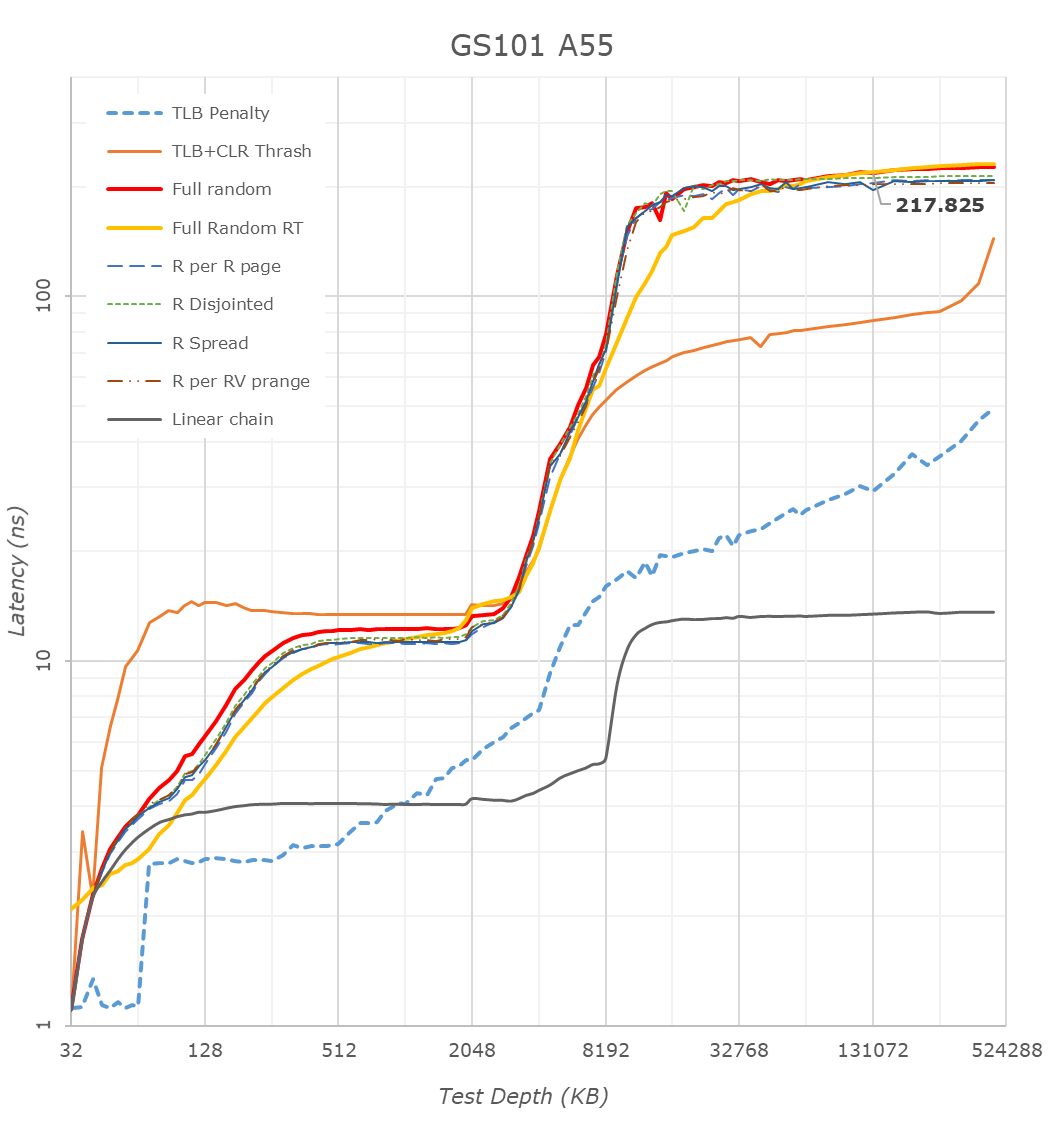
The A55 cores on the Google Tensor have 128KB of L2 cache. What’s interesting here is that because the L3 is on the same clock plane as the Cortex-A55 cores, and it runs at the same higher frequencies, is that the Tensor’s A55s have the lowest L3 latencies of the all the SoCs, as they do without an asynchronous clock bridge between the blocks. Like on the Exynos, there’s some sort of increase at 2MB, something we don’t see on the Snapdragon 888, and I think is related to how the L3 is implemented on the chips.
Overall, the Tensor SoC is quite different here in how it’s operated, and there’s some key behaviours that we’ll have to keep in mind for the performance evaluation part.








108 Comments
View All Comments
Wrs - Wednesday, November 3, 2021 - link
It’s Double data rateNaturalViolence - Wednesday, December 1, 2021 - link
So you're saying the data rate is actually 6400MHz? LPDDR5 doesn't support that. Only regular DDR5 does.Eifel234 - Wednesday, November 3, 2021 - link
I've had the pixel 6 pro for a week now and I have to say it's amazing. I don't care what the synthetic benchmarks say about the chip. It's crazy responsive and I get through a day easily with heavy usage on the battery. At a certain point extra CPU/gpu power doesn't get you anywhere unless your an extreme phone gamer or trying to edit/render videos both of which you should really just do on a computer anyway. What I care mostly about is how fast my apps are opening and how fast the UI is. Theres a video comparison on YouTube of the same apps opening on the iPhone 13 max and the p6 pro and you know what the p6 pro wins handily at loading up many commonly used apps and even some games. Regarding the battery life, I expect to charge my phone nightly so I really don't care if another phone can get me a few more hours of usage after an entire day. I can get 6 hours of SOT and 18 hours unplugged on the battery. More than enough.Lavkesh - Thursday, November 11, 2021 - link
Well that would be true if iOS apps were the same as Android apps. In the review of A15, it was called out how Android AAA games such as Genshin Impact were missing visual effects altogether which were basically present in iOS. These app opening tests are pretty obtuse in my opinion and it checks out as well. For a more meaningful comparison, have a look at this and how badly this so called google soc is spanked by A15!Here's Exynos 2100 vs Google Pixel 6
https://www.youtube.com/watch?v=iDjzPPtC4kU&t=...
Here's Exynos 2100 vs iPhone
https://www.youtube.com/watch?v=U9A91bnVBU4
Arbie - Friday, November 5, 2021 - link
No earphone jack, no sale.JoeDuarte - Saturday, November 6, 2021 - link
This piece has been up for three days, and there are still tons of typos and errors on every page? How is this happening? Why doesn't AnandTech maintain normal standards for publishers? I can't imagine publishing this piece without reading it. And after publishing it, I'd read it again – there's no way I wouldn't catch the typos and errors here. Word would catch many of them, so this is just annoying."...however it’s only 21% faster than the Exynos 2100, not exactly what we’d expect from 21% more cores."
The error above is substantive, and undercuts the meaning of the sentence. Readers will immediately know something is wrong, and will have to go back to find the correct figure, assuming anything at AnandTech is correct.
"...would would hope this to be the case."
That's great. How do they not notice an error like that? It's practically flashing at you. This is just so unprofessional and junky. And there are a lot more of these. It was too annoying to keep reading, so I quit.
ChrisGX - Monday, November 8, 2021 - link
Has Vulkan performance improved with Android 12? That is a serious question. There has been some strange reporting and punditry about the place that seems intent on strongly promoting the idea that the Tensor Mali GPU is endowed with oodles and oodles of usable GPU compute performance.In order to make their case these pundits offer construals of reported benchmark scores of Tensor that appear to muddle fact and fiction. A recent update of Geekbench (5.4.3), for instance, in the view of these pundits, corrects a problem with Geekbench that caused it to understate Vulkan scores on Tensor. So far as I can tell, Primate Labs hasn't made any admission about such a basic flaw in their benchmark software, that needed to be (and has been) corrected, however. The changes in Geekbench 5.4.3, on the contrary, seem to be to improve stability.
I am hoping that there is a more sober explanation for the recent jump in Vulkan scores (assuming they aren't fakes) than these odd accounts that seem intent on defending Tensor from all criticism including criticism supported by careful benchmarking.
Of course, if Vulkan performance has indeed improved on ARM SoCs, then that improvement will also show up in benchmarks other than Geekbench. So, this is something that benchmarks can confirm or disprove.
ChrisGX - Monday, November 8, 2021 - link
The odd accounts that I believe have muddled fact and fiction are linked here:https://chromeunboxed.com/update-geekbench-pixel-6...
https://mobile.twitter.com/SomeGadgetGuy/status/14...