Dissecting Intel's EPYC Benchmarks: Performance Through the Lens of Competitive Analysis
by Johan De Gelas & Ian Cutress on November 28, 2017 9:00 AM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Skylake-SP
- Xeon Platinum
- EPYC
- EPYC 7601
HPC Benchmarks
Discussing HPC benchmarks feels always like opening a can of worms to me. Each benchmark requires a thorough understanding of the software and performance can be tuned massively by using the right compiler settings. And to make matters worse: in many cases, these workloads can be run much faster on a GPU or MIC, making CPU benchmarking in some situations irrelevant.
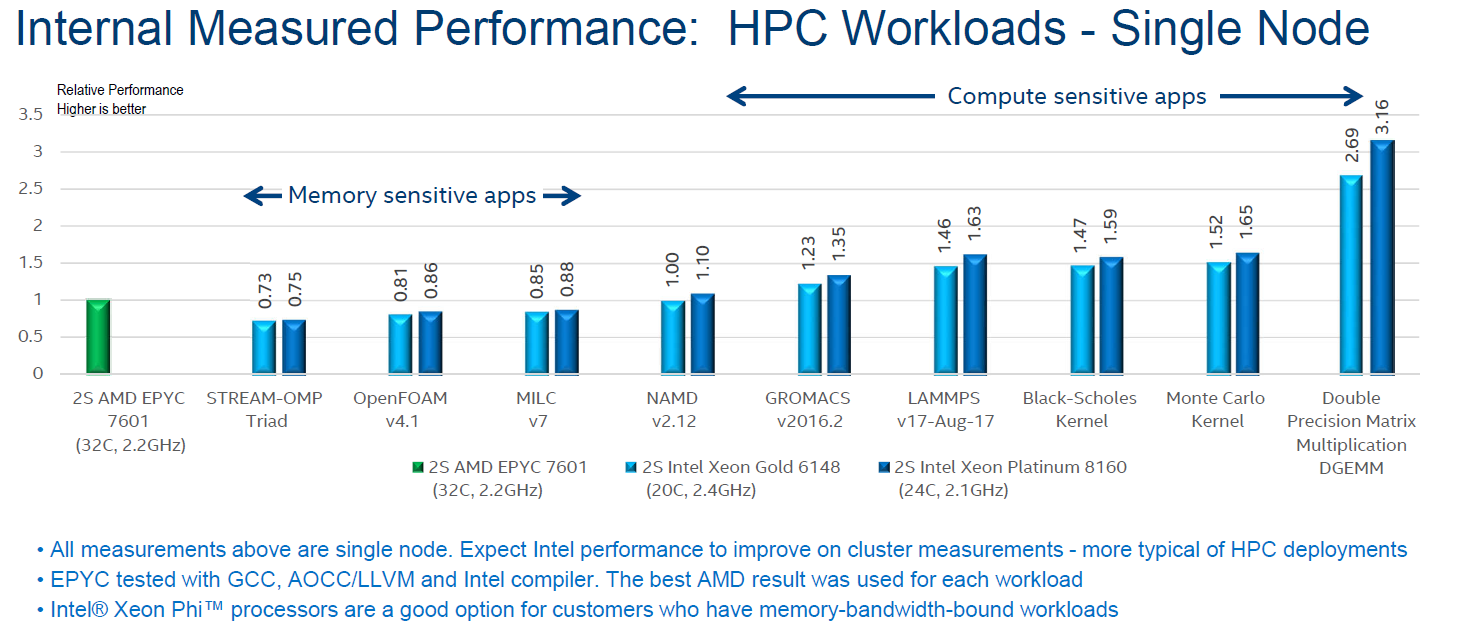
NAMD (NAnoscale Molecular Dynamics) is a molecular dynamics application designed for high-performance simulation of large biomolecular systems. It is rather memory bandwidth limited, as even with the advantage of an AVX-512 binary, the Xeon 8160 does not defeat the AVX2-equipped AMD EPYC 7601.
LAMMPS is classical molecular dynamics code, and an acronym for Large-scale Atomic/Molecular Massively Parallel Simulator. GROMACS (for GROningen MAchine for Chemical Simulations) primarily does simulations for biochemical molecules (bonded interactions). Intel compiled the AMD version with the Intel compiler and AVX2. The Intel machines were running AVX-512 binaries.
For these three tests, the CPU benchmarks results do not really matter. NAMD runs about 8 times faster on an NVIDIA P100. LAMMPS and GROMACS run about 3 times faster on a GPU, and also scale out with multiple GPUs.
Monte Carlo is a numerical method that uses statistical sampling techniques to approximate solutions to quantitative problems. In finance, Monte Carlo algorithms are used to evaluate complex instruments, portfolios, and investments. This is a compute bound, double precision workload that does not run faster on a GPU than on Intel's AVX-512 capable Xeons. In fact, as far as we know the best dual socket Xeons are quite a bit faster than the P100 based Tesla. Some of these tests are also FP latency sensitive.
Black-Scholes is another popular mathematical model used in finance. As this benchmark is also double precision, the dual socket Xeons should be quite competitive compared to GPUs.
So only the Monte Carlo and Black Scholes are really relevant, showing that AVX-512 binaries give the Intel Xeons the edge in a limited number of HPC applications. In most HPC cases, it is probably better to buy a much more affordable CPU and to add a GPU or even a MIC.
The Caveats
Intel drops three big caveats when reporting these numbers, as shown in the bullet points at the bottom of the slide.
Firstly is that these are single node measurements: One 32-core EPYC vs 20/24-core Intel processors. Both of these CPUs, the Gold 6148 and the Platinum 8160, are in the ball-park pricing of the EPYC. This is different to the 8160/8180 numbers that Intel has provided throughout the rest of the benchmarking numbers.
The second is the compiler situation: in each benchmark, Intel used the Intel compiler for Intel CPUs, but compiled the AMD code on GCC, LLVM and the Intel compiler, choosing the best result. Because Intel is going for peak hardware performance, there is no obvious need for Intel to ensure compiler parity here. Compiler choice, as always, can have a substantial effect on a real-world HPC can of worms.
The third caveat is that Intel even admits that in some of these tests, they have different products oriented to these workloads because they offer faster memory. But as we point out on most tests, GPUs also work well here.








105 Comments
View All Comments
Johan Steyn - Monday, December 18, 2017 - link
I am so glad people are realising ANandtechs rubish, probably led by Ian who wrote that terrible Threadripper review. Maybe he will realise it as more complain. It all depends on how much Intel is paying him...mapesdhs - Wednesday, November 29, 2017 - link
ANSYS is one of those cases where having massive RAM really matters. I doubt if any site would bother speccing out a system properly for that. One ANSYS user told me he didn't care about the CPU, just wanted 1TB RAM, and that was over a decade ago.rtho782 - Tuesday, November 28, 2017 - link
> Xeon Platinum 8160 (24 cores at 2.1 - 3.7 GHz, $4702k)$4,702,000? Intel really have bumped up their pricing!!
bmf614 - Tuesday, November 28, 2017 - link
The pricetag discussion really needs to include software licensing as well. Windows Datacenter and SQL server on a machine with 64 cores will cost more than the hardware itself. This is the reason that the Xeon 5122 exists.bmf614 - Tuesday, November 28, 2017 - link
Also isnt it kind of silly to invest in a server platform with limited PCIE performance when faster and faster storage and networking is becoming commonplace?Polacott - Tuesday, November 28, 2017 - link
it really seems that AMD has crushed Intel this time. Also Charlie has some interest points about security ( has this topic being even analyzed here ? https://www.semiaccurate.com/2017/11/20/epyc-arriv... )Software WILL be tuned for Epyc, so a safe bet will not be getting Xeon but Epic, for sure.
And power consumption and heat is really important as is an interesting part of datacenter maintenance costs.
I really don't get how the article ends up in this conclusion.
Johan Steyn - Monday, December 18, 2017 - link
Intel's financial support helps them reach this conclusion. Very sadZolaIII - Tuesday, November 28, 2017 - link
As usually Intel cheated. Clients won't use neither their property compiler nor a software but GNU one's. Now let me show you a difference:https://3s81si1s5ygj3mzby34dq6qf-wpengine.netdna-s...
Other than that this is boring as ARM NUMA based server chips are coming with some backup from good old veterans when it comes to to supercomputing and this time around Intel won't have even a compiler advantage to drag about it.
Sources:
https://www.nextplatform.com/2017/11/27/cavium-tru...
http://www.cavium.com/newsevents-Cray-Catapults-Ar...
Now this are the real news & melancholic ones for me as it brings back memories how it all started. & guess what? We are back their on the start again.
toyotabedzrock - Tuesday, November 28, 2017 - link
Linux 4.15 has code to increase EPYC performance and enable the memory encryption features. 4.16 will have the code to enable the virtual machine memory encryption.duploxxx - Friday, December 1, 2017 - link
thx for sharing the article Johan, as usual those are the ones I will always read.Interesting to get feedback from Intel on benchmark compares, this tells how scared they really are from the competition. There is no way around, I' ve been to many OEM and large vendor events lately. One thing is for sure, the blue team was caught with there pants down and there is for sure interest from IT into this new competitor.
Now talking a bit under the hood, having had both systems from beta stages.
I am sure Intel will be more then happy to tell you if they were running the systems with jitter control. Off course they wont tell the world about this and its related performance issues.
Second, will they also share to the world that there so called AVX enhancement have major clock speed disadvantages to the whole socket. really nice in virtual environments :)
Third, the turbo boosting that is nowhere near the claimed values when running virtualization?
Yes the benchmarking results are nice, but they don't give real world reality, its based on synthetic benches. Real world gets way less turbo boost due to core hot spots and there co-related TDP.
There are reasons why large OEM did not yet introduce EPYC solutions, they are still optimizing BIOS and microcode as they want to bring a solid performing platform. The early tests from Intel show why.
Even the shared VMware bench can be debated with no shared version info as the 6.5u1 has got major updates to the hypervisor with optimizations for EPYC.
Sure DB benches are an Intel advantage, there is no magic to it looking at the die configurations, there are trade offs. But this is ONLY when the DB are bigger then certain amount of dies so we are talking here about 16+ cores from the 32 cores/socket systems for example, anything lower will have actually more memory bandwidth then the Intel part. So how reliable are these benchmarks for a day to day production.... not all are running the huge sizes. And those who do should not just compare based on synthetical benches provided but do real life testing.
Aint it nice that a small company brings a new CPU line and already Intel needs to select there top bin parts as a counter part to show benchmarks to be better. There are 44 other bins available on the Intel portfolio, you can probably already start guessing how well they really fare against there competitor....