The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM EST
For over two years the collective AMD vs Intel personal computer battle has been sitting on the edge of its seat. Back in 2014 when AMD first announced it was pursuing an all-new microarchitecture, old hands recalled the days when the battle between AMD and Intel was fun to be a part of, and users were happy that the competition led to innovation: not soon after, the Core microarchitecture became the dominant force in modern personal computing today. Through the various press release cycles from AMD stemming from that original Zen announcement, the industry is in a whipped frenzy waiting to see if AMD, through rehiring guru Jim Keller and laying the foundations of a wide and deep processor team for the next decade, can hold the incumbent to account. With AMD’s first use of a 14nm FinFET node on CPUs, today is the day Zen hits the shelves and benchmark results can be published: Game On!
[A side note for anyone reading this on March 2nd. Most of the review is done, bar an edit pass or two. Most of the results pages have graphs, but no text. Please have patience while we finish.]
Launching a CPU is like an Onion: There are Layers
As AnandTech moves into its 20th anniversary, it seems poignant to note that one of our first big review pieces that gained notoriety, back in 1997, was on a new AMD processor launch. Our style and testing regime since then has expanded and diversified through performance, gaming, microarchitecture, design, feature-set and debugging marketing strategy. (Fair play to Anand, he was only 14 years old back then…!). Our review for Ryzen aims to encompass many of the areas we feel pertinent to the scale of today’s launch.
An Interview with Dr Lisa Su, CEO of AMD
The Product Launch: A Small Stack of CPUs
Microarchitecture: Front-End, Back-End, micro-op cache, GloFo 14nm LP
Chipsets and Motherboards: AM4 and 300-series
Stock Coolers and Memory: Wraith and DDR4
Benchmarking Performance: Our New 2017 CPU Benchmark Suite
Conclusions
Before the official launch, AMD held a traditional ‘Tech Day’ for key press and analysts in the past week over in San Francisco. The goal of the Tech Day was to explain Zen to the press, before the press explain it to everyone else. AMD likes doing Tech Days, with recent events in memory covering Polaris and Carrizo, and I don’t blame them: alongside the usual slide presentations recapping what is already known or ISSCC/Hot Chips papers, we also get a chance to sit down with the VPs and C-Level executives as well as the key senior engineers involved in the products. Some of the information in this piece we would have published before: AMD’s machine of tickle-out information means that we know a good deal behind the design already, but the Tech Day helps us ask those final questions, along with the official launch details.
So, What Is Zen? Or Ryzen?
A Brief Backstory and Context
The world of main system processors, or CPUs in this case, is governed at a high level by architecture (x86, ARM), microarchitecture (how the silicon is laid out), and process node (such as 28HPM and 16FF+ from TSMC, or 14LP from GloFo). Beyond these we have issues of die area, power consumption, transistor leakage, cost, compatibility, dark silicon, frequency, supported features and time to market.
Over the past decade, both AMD and their main competitor Intel have been competing for the desktop and server computer markets with processors based on the x86 CPU architecture. Intel moved to its leading Core microarchitecture on 32nm around 2010, and is now currently in its seventh generation of it at 14nm, with each generation implementing various front-end/back-end changes and design adjustments to caches and/or modularity (it’s actually a lot more complex than this). By comparison, AMD is running its fourth/fifth generation of Bulldozer microarchitecture, split between its high-end CPUs (running an older 2nd Generation on 32nm), its mainstream graphics focused APUs (running 4th/5th Generation on 28nm), and laptop-based APUs (on 5th Generation).
| High-Performance and Mainstream x86 Microarchitectures |
||||
| AMD | Year | Intel | ||
| Zen | 14FF | 2017 | ? | |
| Excavator v2 | GF28A | 2016 | 14+FF | Kaby Lake |
| Excavator | GF28A | 2015 | 14FF | Skylake |
| Steamroller | 28SHP | 2014 | 14FF | Broadwell |
| - | - | 2013 | 22FF | Haswell |
| Piledriver | 32 SOI | 2012 | 22FF | Ivy Bridge |
| Bulldozer | 32nm | 2011 | 32nm | Sandy Bridge |
| - | - | 2010 | 32nm | Westmere |
| K10 | 45nm | Other | 45nm | Nehalem |
AMD’s Bulldozer-based design was an ambitious goal: typically a processor core will have a single instruction entry point leading to a decode then dispatch to separate integer or floating point schedulers. Bulldozer doubled the integer scheduler and throughput capabilities, and allowed the module to accept two threads of instructions - this meant that integer heavy workloads could perform well, other bottlenecks notwithstanding. The perception was that most OS-based workloads are invariably integer/whole number based, such as loop iterations or true/false Boolean comparisons or predicates. Unfortunately the design ended up with a couple of key issues: OS-based workloads ended up getting more floating-point heavy, traditional OSes didn’t understand how to dispatch work given a dual-thread module leading to overloaded modules (this was fixed with an update), general throughput of a single thread was a small (if any) upgrade over the previous microarchitecture design, and power consumption was high. A number of leading analysts pointed to design philosophies in the Bulldozer design, such as a write-through L1 cache and a shared L2 cache within a module lead to higher latencies and increased power consumption. A good chunk of the deficit to the competition was the lack of a micro-op cache that can help bypass instruction decode power and latency, as well as a process node disadvantage and the incumbent’s strong memory pre-fetch/branch prediction capabilities.
The latest generation of Bulldozer, using ‘Excavator’ cores under the Carrizo name for the chip as a whole, is actually quite a large jump from the original Bulldozer design. We have had extensive reviews of Carrizo for laptops, as well as a review of the sole Carrizo-based desktop CPU, and the final variant performed much better for a Bulldozer design than expected. The fundamental base philosophy was unchanged, however the use of new GPUs, a new metal stack in the silicon design, new monitoring technology, new threading/dispatch algorithms and new internal analysis techniques led to a lower power, higher performance version. This was at the expense of super high-end performance above35W, and so the chip was engineered to focus at more mainstream prices, but many of the technologies helped pave the way for the new Zen floorplan.
Zen is AMD’s new microarchitecture based on x86. Building a new base microarchitecture is not easy – it typically means a large paradigm shift in the way of thinking between the old design and new design in key areas. In recent years, Intel alternates key microarchitecture changes between two separate CPU design teams in the US and Israel. For Zen, AMD made strides to build a team suitable to return to the high-end. Perhaps the most prominent key hire was CPU Architect and all-around praised design guru Jim Keller. Jim has a prominent history in chip design, starting with the likes of Freescale, to developing chips for AMD when they fighting tooth and nail with Intel in the early 2000s, then moving on to Apple to work on the A5/A6 designs. AMD were able to re-hire Jim and put a fire in his belly with the phrase: ‘Make a new high-performance x86 CPU’ (not in those exact simple words…. I hope).

From left to right: Mark Papermaster (CTO AMD), Dr Lisa Su (CEO AMD),
Simon Segars (CEO ARM) and Jim Keller (former AMD, now Tesla)
Jim’s goal was to build the team and lay the groundwork for the new microarchitecture, which for the long-term will revolve around AMD Processor Architect Michael (Mike) Clark. Former Intel engineer Sam Naffziger, who was already working with AMD when the Zen team was put together, worked in tandem with the Carrizo and Zen teams on building internal metrics to assist with power as well. Mark Papermaster, CTO, has stated that over 300 dedicated engineers and two million man-hours have been put into Zen since its inception.
As mentioned, the goal was to lay down a framework. Jim Keller spent three years at AMD on Zen, before leaving to take a position under Elon Musk at Tesla. When we reported that Jim had left AMD, a number of people in the industry seemed confused: Zen wasn’t due for another year at best, so why had he left? The answers we had from AMD were simple – Jim and others had built the team, and laid the groundwork for Zen. With all the major building blocks in place, and simulations showing good results, all that was needed was fine tuning. Fine tuning is more complex than it sounds: getting caches to behave properly, moving data around the fabric at higher speeds, getting the desired memory and latency performance, getting power under control, working with Microsoft to ensure OS compatibility, and working with the semiconductor fabs (in this case, GlobalFoundries) to improve yields. None of this is typically influenced by the man at the top, so Jim’s job was done.
This means that in the past year or so, AMD has been working on that fine tuning. This is why we’ve slowly seen more and more information coming out of AMD regarding microarchitecture and new features as the fine-tuning slots into place. All this culminates in Ryzen, the official name for today’s launch.
Along with the new microarchitecture, Zen is the first CPU from AMD to be launched on GlobalFoundries’ 14nm process, which is semi-licenced from Samsung. At a base overview, the process should offer 30% better efficiency over the 28nm HKMG (high-k metal gate) process used at TSMC for previous products. One of the issues facing AMD these past few years has been Intel’s prowess in manufacturing, first at 22nm and then at 14nm - both using iterative FinFET generations. This gave an efficiency and die-size deficit to AMD through no real fault of their own: redesigning older Bulldozer-derived products for a smaller process is both difficult and gives a lot of waste, depending on how the microarchitecture as designed. Moving to GloFo’ 14nm on FinFET, along with a new microarchitecture designed for this specific node, is one stepping stone to playing the game of high-end CPU performance.
But returning to high-end CPU performance is difficult. There are two crude ways to measure performance: overall throughput, or per-core throughput. Having a low per-core throughput but using lots and lots of cores to increase overall throughput already has a prime example in graphics cards, which are mainly many small dedicated vector processors in a single chip. For general purpose computing, we see designs such as ThunderX putting 64+ ARM cores in a single chip, or Intel’s own Xeon Phi that has up to 72 x86 cores as a host processor (among others). All of these have relatively low general purpose single-core performance, either due to the fact that they focus on specific workloads, their architecture, or they have to run at super-low frequency to be within a particular power budget. They’re still high-performance, but the true crown lies with a good per-core performance. Per-core is where Intel has been winning, and the latest Skylake/Kaby Lake microarchitecture holds the lead due to the way the core is designed, tuned, and produced on arguably the most competitive manufacturing process node geared towards high performance and efficiency.
With the Zen microarchitecture, AMD’s goal was to return to high-end CPU performance, or specifically having a competitive per-core performance again. Trying to compete with high frequency while blowing the power budget, as seen with the FX-9000 series running at 220W, was not going to cut it. The base design had to be efficient, low latency, be able to operate at high frequency, and scale performance with frequency. Typically per-core performance is measured in terms of ‘IPC’, or instructions per clock: a processor that can perform more operations or instructions per Hz or MHz has a higher performance when all other factors are equal. In AMD’s initial announcements on Zen, the goal of a 40% gain in IPC was put into the ecosystem, with no increase in power. It is pertinent to say that there were doubts, and many enthusiasts/analysts were reluctant to claim that AMD had the resources or nous to both increase IPC by 40% and maintain power consumption. In normal circumstances, without a significant paradigm shift in the design philosophy, a 40% gain in efficiency can be a wild goose chase. Then it was realised that AMD were suggesting a +40% gain compared to the best version of Bulldozer, which raised even more question marks. At the formal launch last week, AMD stated that the end goal was achieved with +52% in industry standard benchmarks such as SPEC from Piledriver cores (with an L3 cache) or +64% from Excavator cores (no L3 cache).
Moving nearer to the launch, and with more details under our belts, it was clear that AMD were not joking but actually being realistic. Analyzing what we were told about the core design (we weren’t told everything to begin with) would seem to suggest that AMD, through this long-term CPU team and core design plan, have all the blocks in place necessary to do the deed. Aside from getting an actual chip on hand to test, analysts were still concerned about AMD’s ability to execute both on time and sufficiently to make a dent and recreate a highly competitive x86 market.
Throughout the lifetime of the Zen concept at AMD, they have seen a couple of corporate restructurings, changes at the high C-level executives, time when the company value dipped below the company asset value, restructuring of manufacturing and wafer deals with GlobalFoundries (which was spun out of AMD before Zen), sale and re-lease of major corporate buildings, and the integration/de-integration of the graphics team within the company. Within all that, Bulldozer didn’t make the impact it needed to, in part due to pre-launch hype and underwhelming results. Sales volumes have been declining (partly due to lower global PC demand), and server-based revenues have dropped to almost nil as we’ve not seen a new Opteron in five years. In short, revenue has been decreasing. AMD’s ability to get their finances under control, and then focus and execute, has been under question.
In the past few months, that outlook has changed. The top four executives involved in Zen, Dr. Lisa Su (CEO), Mark Papermaster (CTO), Jim Anderson (CVP Client) and Forrest Norrod (CVP Server), have been stable in the company for a few years, and all four have that air of quiet confidence. It is rather surprising to see three traditional processor engineers at the top of the chain for a CPU launch, rather than a sales or marketing focused executive – typically an engineer releasing a product with a grin on their face is often a good sign. Apart from that, AMD’s semi-custom revenues have increased through securing deals with the leading consoles, the GPU side of the company (Radeon Technology Group, headed under Raja Koduri) successfully executed at 14nm with mainstream parts in 2016, and for that confidence has AMD now trading at over $12/share, just under their 2004/2005 peak. At the minute a large number of individuals and companies are invested in AMD succeeding, both consumers and financials alike, and recent performance on execution has been a positive factor.
Since August, AMD has been previewing the Zen microarchitecture in actual pre-production silicon, running Windows and running benchmarks. With the 40%+ gain in IPC constantly being quoted, and now a +52% being presented, most users and interested parties want to know exactly where it sits compared to an equivalent Intel product. Back in August AMD performed a single, almost entirely dismissible, benchmark showing equivalent IPC of Zen with Broadwell-E (read our write up on that here, and reasons why it’s difficult to interpret a single benchmark). AMD had a ‘New Horizons’ (Ho-Ryzen, get it?) event in December and announcements at CES in January showing performance in gaming and encoding, in particular Handbrake. It is worth noting that Intel, as you would expect any competitor, went through each open source project AMD had used an implemented updates to assist dead/bad code (e.g. coalescing read/writes to comply with AMD/Intel design guidelines) or offer improvements (adding in 256-bit vector codes to combine consecutive 128-bit compute*), which is why some of the results from the launch today are different from what AMD has shown. (If anyone thinks this is ‘unfair’, it begs a bigger question as to how IPC is a good measure of performance if the code is IPC limiting itself, which is a topic for another day.) At the Tech Day, AMD went into further detail regarding various internal benchmarks, both CPU and gaming related, showing either near parity or a fair distribution of win/loss metrics, but ultimately giving better price/performance.
*In this instance, having 4 x 128-bit vector math usually creates 4 ops. Arranging code to 256-bit can give 2 x 256-bit for two ops, which takes two cycles on Zen per core but only one cycle on Intel’s latest.
Recently AMD held a talk at ISSCC (the International Solid State Circuits Conference), which we’ll go into as part of this review, but one thing is worth mentioning here. Along with AMD requiring Zen to have good single thread performance, they also wanted something small. At ISSCC, AMD showed a slide comparing a Zen die shot to a ‘competitor’ (probably Skylake) die area:
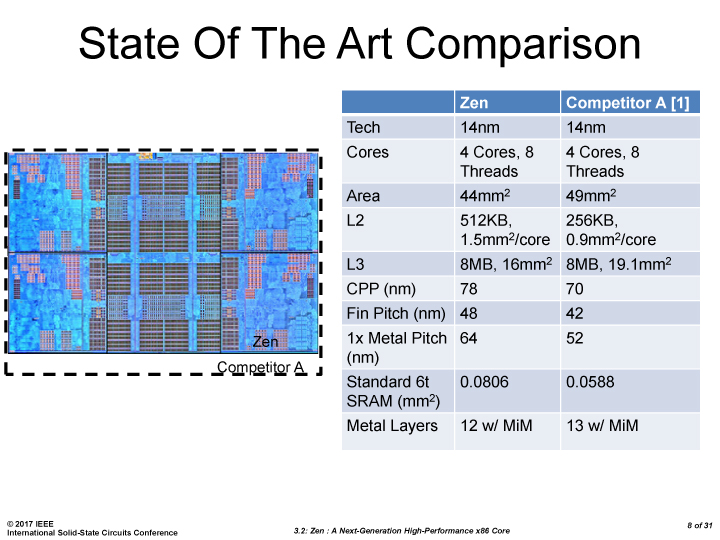
Here AMD is comparing a four-core part to a four-core part, showing that while AMD’s L2 is bigger, the fin pitch is larger, the metal pitch is larger, and its SRAM cells are larger, the quad core design on 14nm GloFo is smaller than 14nm Intel. This is practically due to the way the Zen cores are designed vs. Intel cores – the simple explanation is that the Intel cores have wider execution ports (such as processing a 256-bit vector in one micro-op rather than two) and, we suspect, a larger area dedicated to pre-fetch logic. There’s also the consideration of dark silicon, to help assist the thermal environment around the logic units, which is undisclosed.
I mention this because one of AMD’s goals, aside from the main one of 40%+ IPC, is to have small cores. As a result, as we’ll see in this review, various trade-offs are made. Rather than dedicating a larger die area to execution ports that support AVX in one go, AMD decided to use 2x128-bit vector support (as 1x256) but increase the size of the L2 cache. A larger L2 will ensure fewer cache misses in varied code, perhaps at the expense of high-end compute which can take advantage of larger vectors. The larger L2 will help with single thread performance (all other factors being equal), and AMD knows that Intel’s cache is high performance, so we will see other trade-offs like this in the design. This is obviously combined with AMD’s recent work on having high-density libraries for cache and compute.
AMD has already set out a roadmap for different markets with products based on the Zen microarchitecture. Today’s launch is the first product line, namely desktop-class processors under the Ryzen 7 family name. Following Ryzen 7 will be Ryzen 5 (Q2) and Ryzen 3 (2H17) for the desktop. There is also AMD’s new server platform, Naples, featuring up to 32 cores on a single CPU (we’ll discuss Naples later in the review). We expect Naples to be in the Q2/Q3 timeframe. In the second half of this year (Q3/Q4), AMD is planning to launch mobile processors based on Zen, called Raven Ridge. This processor line-up will most likely be with integrated graphics, and it will be interesting to see how well the microarchitecture scales down into low power. As Ryzen CPUs are geared towards a more performance focused audience, and the fact that they lack integrated graphics, AMD will also maintain its line of ‘Bristol Ridge’ platform (Excavator based processors that also support the 300-series socket). The goal of Bristol Ridge is to fill in at the low end, or for systems that want the option of discrete graphics. Given what we’ve seen in benchmarks, despite recent statements from AMD to the contrary, the FX-line of AM3+ CPUs seems to be coming to an end.
For users looking to go buy parts today, here’s the pertinent information you need to know. The Ryzen CPUs will form part of the ‘Summit Ridge’ platform – ‘Summit Ridge’ indicates a Ryzen CPU with a 300-series chipset (X370, B350, A320). Both Bristol Ridge and Summit Ridge, and thus Ryzen, mean that AMD makes the jump to a desktop platform that supports DDR4 and a high-end desktop platform that supports PCIe 3.0 natively. These CPUs use the AM4 socket on the 300-series motherboards, which is not compatible with any of AMD’s previous socket designs, and also has slightly different socket hole distances for CPU coolers that don’t use AMD’s latch mechanism. Despite the socket hole size change, AMD has kept the latch mechanism in the same place, but coolers that have their own backplates will need new supporting plates to be able to be used (we’ve got a bit on this later in the review as well).








574 Comments
View All Comments
deltaFx2 - Wednesday, March 8, 2017 - link
@Meteor2: No. Consumer GPUs have poor throughput for Double precision FP. So you can't push those to the GPU (unless you own those super-expensive Nvidia compute cards). Apparently, many rendering/video editing programs use GPUs for preview but do the final rendering on CPU. Quality, apparently, and might be related to DP FP. I'm not the expert, so if you know otherwise, I'd be happy to be corrected and educated. Also, you could make the same argument about AVX-256.The quoted paragraph is probably the only balanced statement in that entire review. Compare the tone of that review with AT review above.
On an unrelated note, there's the larger question of running games at low res on top-end gpus and comparing frame-rates that far exceed human perception. I know, they have to do something, so why not just do this. The rationale is: " In future a faster GPU in future will create a bottleneck ". If this is true, it should be easy to demonstrate, right? Just dig through a history of Intel desktop CPUs paired with increasingly powerful GPUs and see how it trends. There's not one reviewer that has proven that this is true. It's being taken as gospel. OTOH, plenty of folks seem happy with their Sandy Bridge + Nvidia 1080, so clearly the bottleneck isn't here 5 years after SB. Maybe, just maybe, it's because the differences are imperceptible?
Ryzen clearly has some bottlenecks but the whole gaming thing is a tempest in a tea-cup.
theuglyman0war - Thursday, March 9, 2017 - link
ZBRUSHprobably 90% of all 3d assets that are created from concept ( NOT SCANNED )
Went through Zbrush at some point.
Which means no GPU acceleration at all.
Renderman
Maxwell
Vray
Arnold
still all use CPU rendering As do a mountain of other renderers.
Arnold will be getting an option
But the two popular GPU renderers are Otoy Octane and Redshift...
The have their excellent expensive place. But the majority of rendering out there is still suffered through software rendering. And will always be a valid concern as long as they come FREE built into major DCC applications.
theuglyman0war - Thursday, March 9, 2017 - link
Saw that same GPU trumps CPU render validity concerns...Comment and had a good laugh.
I'll remember to spread that around every time I see Renderman Vray Arnold Maxwell sans GPU rendering going on.
Or the next time a Mercury engine update negates all non Quadro GPU acceleration.
To be fair a lot of creative pros and tech artists seem to disagree with me but...
The only time between pulling vrts in Maya and brushing a surface in Zbrush that I really feel that I am suffering buckets of tears and desire a new CPU ( still on i7-980x ) is when I am cussing out a progress bar that is teasing me with it's slow progress. And that means CORES! encoding... un compressing... Rendering! Otherwise I could probably not notice day to day on a ten year old CPU. ( excluding CPU bound gaming of course... talking bout day to day vrt pulling )
I was just as productive in 2007 as I am today.
MaidoMaido - Saturday, March 4, 2017 - link
Been trying to find a review including practical benchmarks for common video editing / motion graphics applications like After Effects, Resolve, Fusion, Premiere, Element 3D.In a lot of these tasks, the multithreading is not always the best, as a result quad core 6700K often outperforms the more expensive Xeon and 5960X etc
deltaFx2 - Saturday, March 4, 2017 - link
I would recommend this response to the GamersNexus hit piece: https://www.reddit.com/r/Amd/comments/5xgonu/analy...The i5 level performance is a lie.
Notmyusualid - Saturday, March 4, 2017 - link
@ deltaFx2Sorry, not reading a 4k worded response. I'll wait for Anand to finish its Ryzen reviews before I draw any final conclusions.
Meteor2 - Tuesday, March 7, 2017 - link
@deltaFX2 RE: in the 4k word Reddit 'rebuttal', what that person seems to be saying, is that once you've converted your $500 Ryzen 1800X into a 8C/8T chip, _then_ it beats a $240 i5, while still falling short of the $330 i7. Out-of-the-box, it has worse gaming performance than either Intel chip.That's not exactly a ringing endorsement.
The analysis in the Anandtech forums, which concludes that in a certain narrow and low power band a heavily down-clocked 1800X happens to get excellent performance/W, isn't exactly thrilling either.
deltaFx2 - Wednesday, March 8, 2017 - link
@ Meteor2: The anandtech forum thing: Perf/watt matters for servers and laptop. Take a look at the IPC numbers too. His average is that Zen == Broadwell IPC, and ~10% behind Sky/Kaby lake (except for AVX256 workloads). That's not too shabby at all for a $300 part.You completely missed the point of the reddit rebuttal. The GN reviewer drops i5s from plenty of tests citing "methodological reasons", but then says R7==i5 in gaming. The argument is that plenty of games use >4 threads and that puts i5 at a disadvantage.
tankNZ - Sunday, March 5, 2017 - link
yes I agree, it's even better than okay for gaming[img]http://smsh.me/li3a.png[/img]deltaFx2 - Monday, March 6, 2017 - link
You may wish to see this though: https://forums.anandtech.com/threads/ryzen-strictl... Way, way, more detailed than any tech media review site can hope to get. No, it's got nothing to do with gaming. Gaming isn't the story here. AMD's current situation in x86 market share had little to do with gaming efficiency, but perf/watt.I'll quote the author: "850 points in Cinebench 15 at 30W is quite telling. Or not telling, but absolutely massive. Zeppelin can reach absolutely monstrous and unseen levels of efficiency, as long as it operates within its ideal frequency range."